
python万字博文教你玩嗨selenium库,建议收藏!
发布于2021-07-25 07:08 阅读(651) 评论(0) 点赞(19) 收藏(1)
python万字博文教你玩嗨selenium库,建议收藏!
首先安装插件
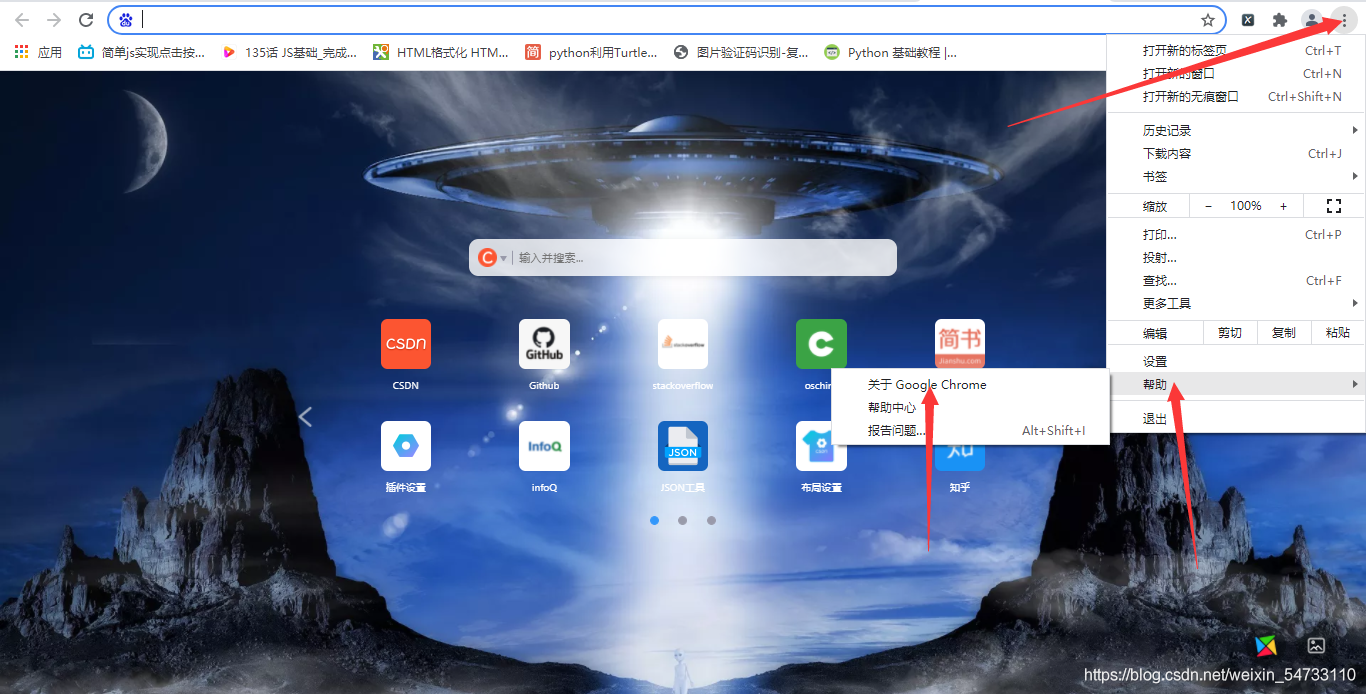
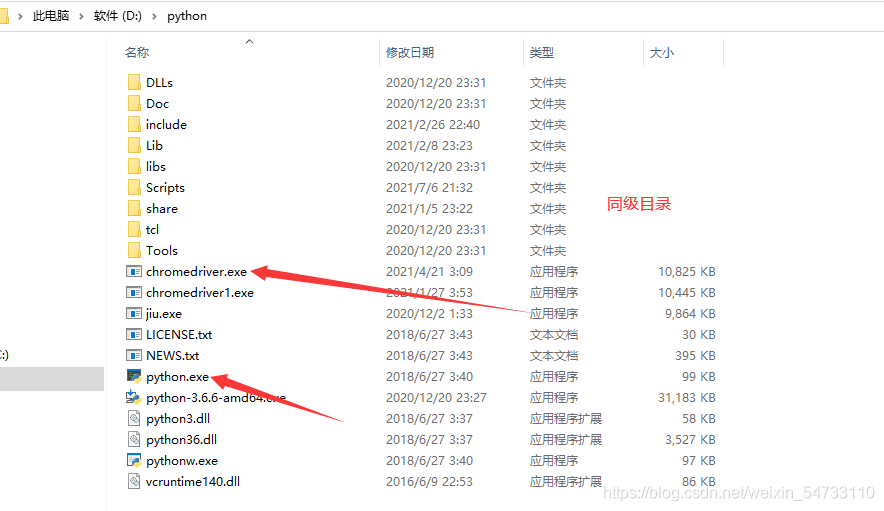
首先要安装webdriver插件,本文以谷歌浏览器为例,点开谷歌浏览器,点击右上角三个点,然后点击帮助,然后点击关于Google Chrome,查看浏览器的版本,然后点击网址http://npm.taobao.org/mirrors/chromedriver寻找自己浏览器对应的版本进行下载,下载之后将chromedriver.exe的文件最好放在你python解释器的同级目录下

基本用法
from selenium import webdriver
driver = webdriver.Chrome(executable_path=r'你的chromedriver.exe的路径')
start_url = 'https://www.baidu.com'
driver.get(start_url)
无界面模式运行,后台运行
第一种无界面模式
from selenium import webdriver
from selenium.webdriver import ChromeOptions
# 创建配置对象
option = ChromeOptions()
# 无界面的设置
option.headless = True
driver = webdriver.Chrome(options=option)
driver.get('https://www.baidu.com')
# 获取网页的源码
html = driver.page_source
print(html)
无界面模式第二种
from selenium import webdriver
from selenium.webdriver import ChromeOptions
# 创建配置对象
option = ChromeOptions()
# 无界面的设置
option.add_argument('--headless')
driver = webdriver.Chrome(options=option)
driver.get('https://www.baidu.com')
# 获取网页的源码
html = driver.page_source
print(html)
第三种无界面模式
from selenium import webdriver
driver = webdriver.PhantomJS(executable_path=r'你的phantomjs.exe路径')
# driver = webdriver.phantomjs(executable_path=r'D:\python3.7\utils\phantomjs.exe')
driver.get('https://www.baidu.com')
# 获取网页的源码
html = driver.page_source
print(html)
标签定位方法
from selenium import webdriver
driver = webdriver.Chrome()
# 窗口最大化
driver.maximize_window()
start_url = 'https://www.baidu.com'
# start_yrl_1 = 'https://www.csdn.net'
# 访问地址
driver.get(start_url)
根据标签的id属性进行定位
# 根据标签的id属性进行定位
"""根据标签的id属性进行定位,如果浏览器页面展示的是输入,采用send_keys(),如果是按钮点击的,使用click()"""
driver.find_element_by_id('kw').send_keys('美女')
driver.find_element_by_id('su').click()
根据标签的name属性进行定位
driver.find_element_by_name('wd').send_keys('迪丽热巴')
根据标签的class属性进行定位
driver.find_element_by_class_name('s_ipt').send_keys('迪丽热巴')
根据xpath语法定位
driver.find_element_by_xpath('//*[@id="su"]').click()
根据CSS语法定位
driver.find_element_by_css_selector('#su').click()
浏览器页面的关闭与退出
from selenium import webdriver
import time
driver = webdriver.Chrome()
start_url = 'https://www.baidu.com'
start_url_1 = 'https://www.csdn.net'
driver.get(start_url)
time.sleep(5)
"""通过执行js代码,打开浏览器窗口,访问地址"""
js = 'window.open("{}")'.format(start_url_1)
driver.execute_script(js)
time.sleep(5)
# 浏览器窗口的关闭
driver.close()
# 退出浏览器
driver.quit()
页面的滑动
from selenium import webdriver
import time
driver = webdriver.Chrome()
start_url = 'https://www.csdn.net'
driver.get(start_url)
time.sleep(5)
# 滑动固定距离
# js = 'scrollTo(0, 2000)'
# driver.execute_script(js)
for i in range(5):
js = f'scrollTo(0, {(i+1)*800})'
driver.execute_script(js)
time.sleep(1.5)
窗口切换
from selenium import webdriver
import time
driver = webdriver.Chrome()
start_url = 'https://www.baidu.com'
start_url_1 = 'https://www.csdn.net'
driver.get(start_url)
time.sleep(5)
"""通过执行js代码,打开浏览器窗口,访问地址"""
js = 'window.open("{}")'.format(start_url_1)
driver.execute_script(js)
time.sleep(5)
"""获取浏览器所有窗口:注意点:窗口的切换是通过下标控制的"""
win = driver.window_handles
# 执行切换
driver.switch_to.window(win[1])
time.sleep(2)
driver.switch_to.window(win[0])
time.sleep(2)
driver.switch_to.window(win[1])
time.sleep(2)
driver.switch_to.window(win[0])
# 浏览器窗口的关闭
driver.close()
# 退出浏览器
driver.quit()
页面的切换
from selenium import webdriver
driver = webdriver.Chrome()
start_url = 'https://mail.163.com/'
driver.get(start_url)
"""定位不成功,在有的情况是因为有页面的嵌套导致的
在一个html源码中有多个html页面,示例:一个html嵌套一个html
以上:又称之为iframe的嵌套
"""
# 定位嵌套位置iframe
el_iframe = driver.find_elements_by_tag_name('iframe')
# 执行iframe的切换
driver.switch_to.frame(el_iframe[0])
# 标签定位
driver.find_element_by_name('email').send_keys('邮箱账号')
driver.find_element_by_name('password').send_keys('你的邮箱密码')
driver.find_element_by_id('dologin').click()
强制等待
import time
time.sleep(3)
隐式等待
等待一个标签需要6秒钟进行渲染,设置等待时间为10s,我们的程序,在等待6秒钟后,即可执行下一步
数据加载完成,立马执行下一步
from selenium import webdriver
from selenium.webdriver import ChromeOptions
driver = webdriver.Chrome()
url = 'https://www.kuwo.cn/search/list?key=%E6%9E%97%E4%BF%8A%E6%9D%B0'
driver.get(url)
driver.implicitly_wait(10)
driver.find_element_by_xpath('//*[@id="__layout"]/div/div[2]/div/div[2]/div[2]/div[2]/div[1]/ul/li[1]/div[2]/a').click()
显示等待
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.by import By
from selenium import webdriver
driver = webdriver.Chrome()
driver.maximize_window()
driver.get('https://www.baidu.com')
# 通过文本名称进行定位
# driver.find_element_by_link_text('人工智能').click()
WebDriverWait(driver, 20, 0.5).until(EC.presence_of_element_located((By.LINK_TEXT, '地图'))).click()
"""
参数20表示最长等待20s
参数0.5表示0.5s检查一次规定的标签书否存在
EC.presence_of_all_elements_located((By.LINK_TEXT, '地图')):通过文本内容定位标签
每0.5s一次检查,通过链接文本内容定位标签是否存在,如果存在就向下继续执行,如果不存在20s上限就报错
"""
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.by import By
from selenium import webdriver
driver = webdriver.Chrome()
driver.maximize_window()
driver.get('https://www.csdn.net')
# 通过文本名称进行定位
driver.find_element_by_link_text('人工智能').click()
WebDriverWait(driver, 20, 0.5).until(EC.presence_of_element_located((By.XPATH, '//*[@id="floor-nav_557"]/div/div/div[2]/ul/li[1]/a'))).click()
鼠标悬停
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
driver = webdriver.Chrome()
import time
start_url = 'https://lceda.cn/'
driver.get(start_url)
# 定位到需要悬停的标签
move = driver.find_element_by_xpath('//*[@id="headerNav"]/li[1]/a/span')
# 悬停之后需要点击的标签
a = driver.find_element_by_xpath('/html/body/div[1]/div[2]/div[1]/div[1]/div[3]/div[1]/a[2]')
# 悬停点击执行
# 创建事件对象
actions = ActionChains(driver)
time.sleep(1)
# 记录操作
actions.move_to_element(move)
time.sleep(1.5)
# 悬停的点击
actions.click(a)
time.sleep(1)
# 开始执行事件
actions.perform()
使用代理
from selenium import webdriver
import time
options = webdriver.ChromeOptions()
options.add_argument('--proxy-server=http://ip地址') # 代理IP:端口号
# ${chromedriver_path}: chromedriver驱动存放路径
driver = webdriver.Chrome(options=options)
driver.get("https://dev.kdlapi.com/testproxy")
# 获取页面内容
print(driver.page_source)
# 延迟3秒后关闭当前窗口,如果是最后一个窗口则退出
time.sleep(3)
driver.close()
替换ua
from selenium import webdriver
import time
agent = 'Mozilla/5.0 (iPad; CPU OS 11_0 like Mac OS X) AppleWebKit/604.1.34 (KHTML, like Gecko) Version/11.0 Mobile/15A5341f Safari/604.1'
options = webdriver.ChromeOptions()
options.add_argument('--user-agent=' + agent)
# ${chromedriver_path}: chromedriver驱动存放路径
driver = webdriver.Chrome(options=options)
driver.get("https://www.baidu.com")
# 获取页面内容
print(driver.page_source)
# 延迟3秒后关闭当前窗口,如果是最后一个窗口则退出
time.sleep(3)
模拟登陆与继续请求
cookie_list = [
'''cookie列表'''
]
import random
from requests_html import HTMLSession
session = HTMLSession()
for i in range(3):
url_1 = 'https://www.douban.com'
headers = {
'Cookie': random.choice(cookie_list),
'Host': 'www.douban.com',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36'
}
response = session.get(url_1, headers=headers).html
print(response.xpath('//*[@id="db-global-nav"]/div/div[1]/ul/li[2]/a/span[1]/text()'))
from selenium import webdriver
driver = webdriver.Chrome()
from requests_html import HTMLSession
session = HTMLSession()
driver.maximize_window()
start_url = 'https://www.douban.com'
import time
# 访问
driver.get(start_url)
time.sleep(0.5)
iframe_div = driver.find_element_by_tag_name('iframe')
# 执行切换
driver.switch_to.frame(iframe_div)
# 定位点击密码登录
driver.find_element_by_xpath('/html/body/div[1]/div[1]/ul[1]/li[2]').click()
# 通过name属性定位标签,输入账号
driver.find_element_by_name('username').send_keys('账号')
driver.find_element_by_id('password').send_keys('密码')
driver.find_element_by_xpath('/html/body/div[1]/div[2]/div[1]/div[5]/a').click()
time.sleep(5)
# 获取登录之后的cookie
cookie_list = driver.get_cookies()
# 转化cookie
cookie_dict = {cook['name']: cook['value'] for cook in cookie_list}
print(cookie_dict)
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36'
}
response = session.get(start_url, headers=headers, cookies=cookie_dict).html
print(response.xpath('//*[@id="db-global-nav"]/div/div[1]/ul/li[2]/a/span[1]/text()'))
原文链接:https://blog.csdn.net/weixin_54733110/article/details/119027005
所属网站分类: 技术文章 > 博客
作者:小酷狗
链接:http://www.pythonpdf.com/blog/article/407/e8e8459db5c013ff6c01/
来源:编程知识网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)