
利用Scrapy爬取前程无忧
发布于2021-07-25 07:23 阅读(1136) 评论(0) 点赞(30) 收藏(4)
1. 预备知识
python语言,scrapy爬虫基础,正则表达式
2. 抓取目标结构
- 职位列表中的以下信息:

- 点击职位,进入职位详情页中,提取以下信息:

3.抓包分析
3.1 抓包分析url地址
先进入到我们的页面中来,选择想要爬取的城市,url地址会发生相应的变化并刷新,如下图所示:
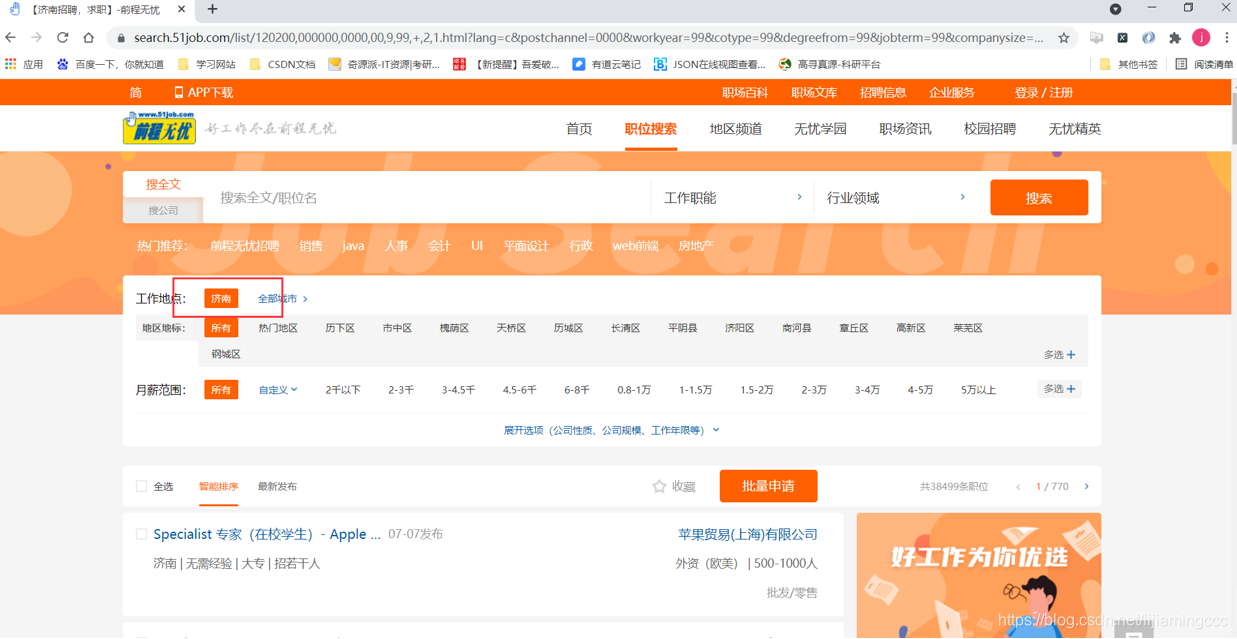
复制地址栏的url链接地址如下:https://search.51job.com/list/120200,000000,0000,00,9,99,+,2,1.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=
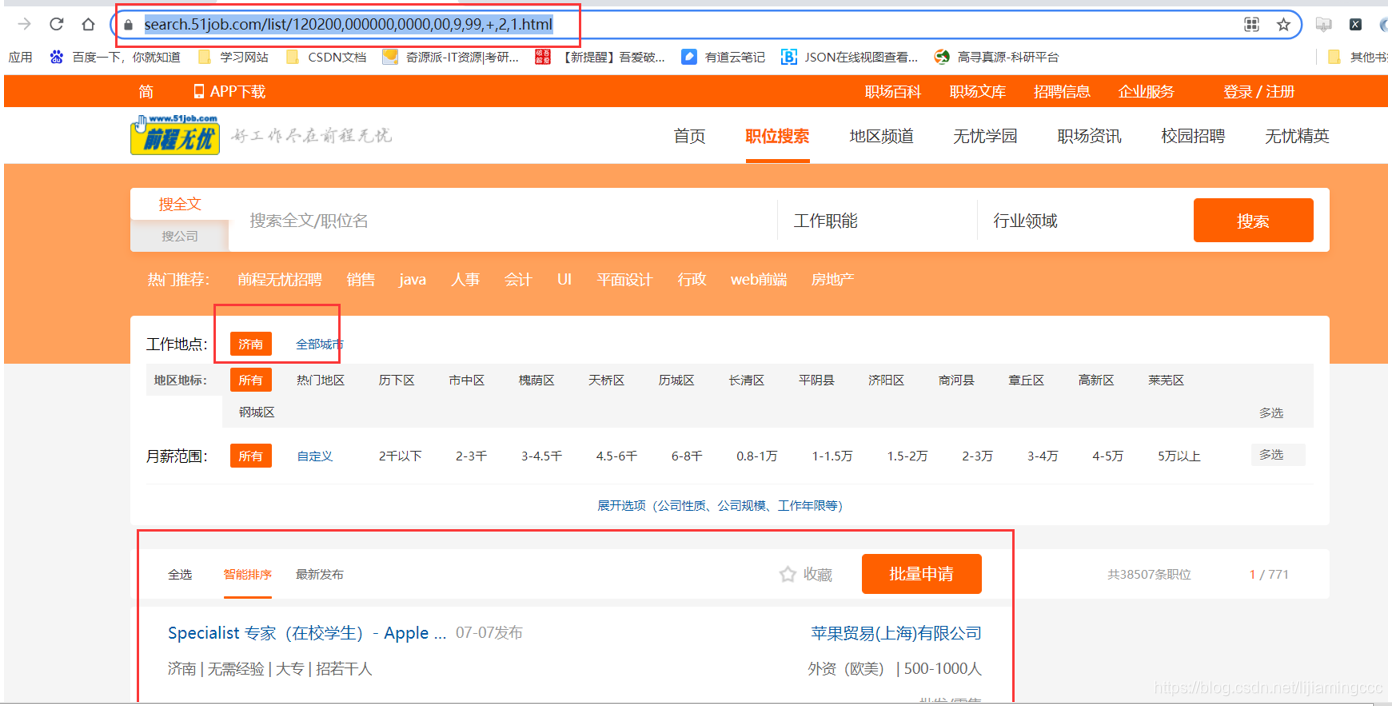
根据第三章学到的知识,我们尝试对该url链接进行删减并测试删减后的url是否对访问结果产生影响,测试后删减的url结果如下:
https://search.51job.com/list/120200,000000,0000,00,9,99,+,2,1.html
访问并对比原网页可以发现,删减参数后的url地址所请求的页面,与原url请求的网页相差不大,均存在我们想要提取的信息。
结果如下:
3.2 分析页码规律
我们先打开删减版的url对应的页面,为了分析页码请求数据的规律,我们先将滑块移到最后,点击抓包工具中的clear按钮,清空当前存在的请求列表,防止之前存在的请求列表对我们的分析进行干扰,最后,点击第二页,查看抓包工具抓取到的url链接,同时注意url地址栏的变化情况,操作如下所示:
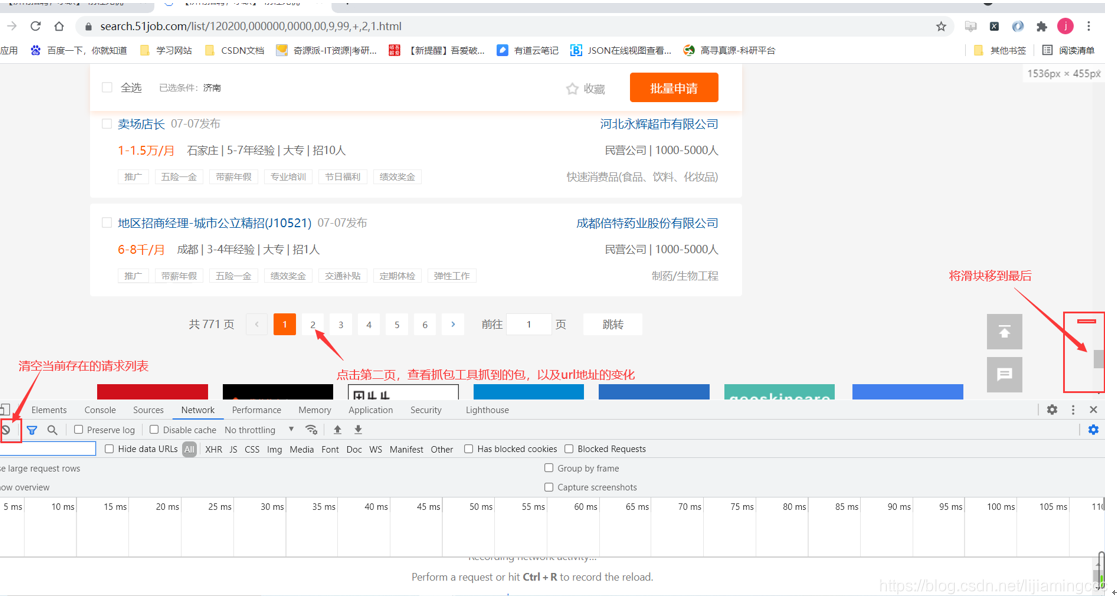
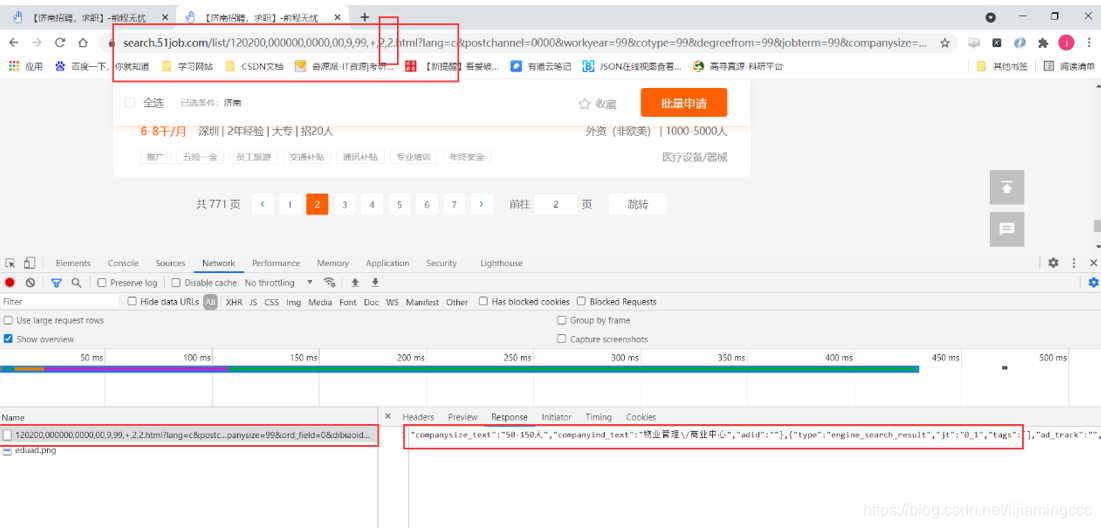
分析上图,我们可以看到数据依然是通过ajax异步传递的,同时url链接再次变成了众多参数的url,但是这里我们可以发现url地址的变化有非常关键的一点:
原来的url链接:https://search.51job.com/list/120200,000000,0000,00,9,99,+,2,1.html
变成了以下链接:
https://search.51job.com/list/120200,000000,0000,00,9,99,+,2,2.html
3.3分析数据存储位置
我们尝试将抓到的ajax的请求进行访问时,得到了以下结果:
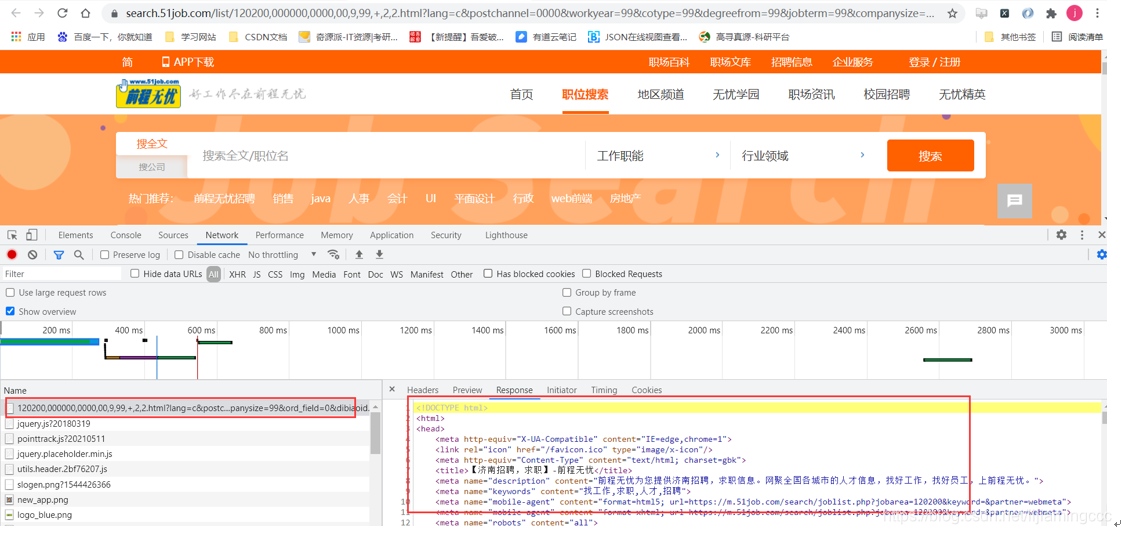
单独进行这条链接的请求,返回的只能是整个前端的页面数据,并不像我们想象中的是一些json格式的字符串,所以我们没有办法利用上一章实验的思路进行数据提取,只能通过分析url的响应,查找数据存在的位置。
接下来我们尝试查找数据存在的位置,首先,复制前端咱们想要抓取的数据,在全局中搜索这段数据出现的位置以及所对应的url链接,然后抓包工具的network模块找到这条url,按ctrl+f进行搜索,流程如下图所示:
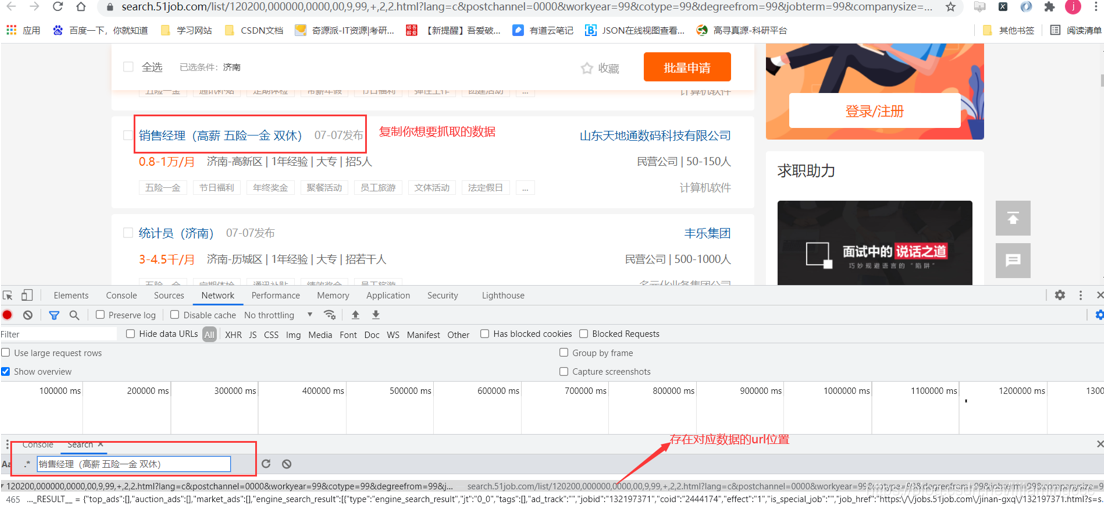
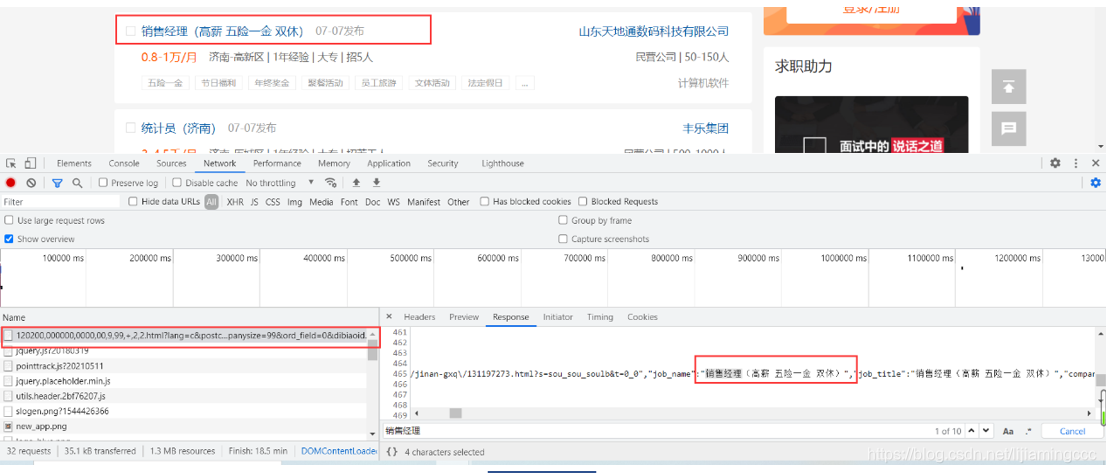
可以看到数据 是存放在url对应的响应中的script标签下,我们可以尝试用正则表达式进行匹配。
4. 正则表达式的应用
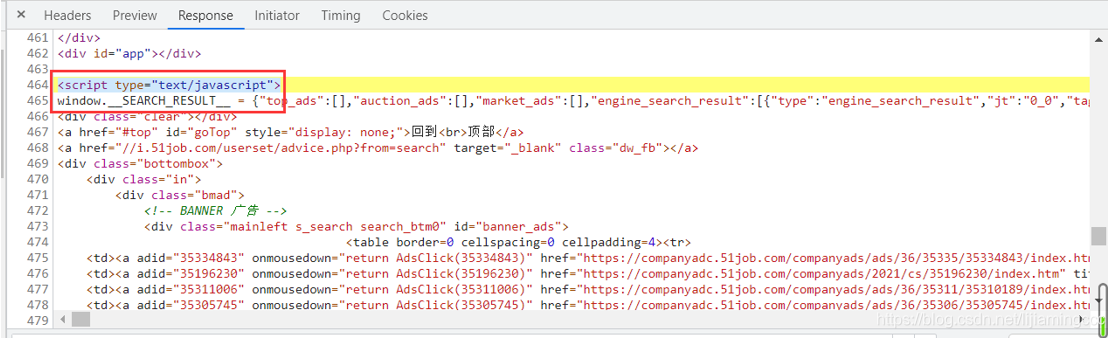
首先,找到想要提取的数据前后的字符存在规律,例如:在本章中,“window.SEARCH_RESULT = ”是json数据前面的字符串,“”是json数据后面的字符串,如下图所示:
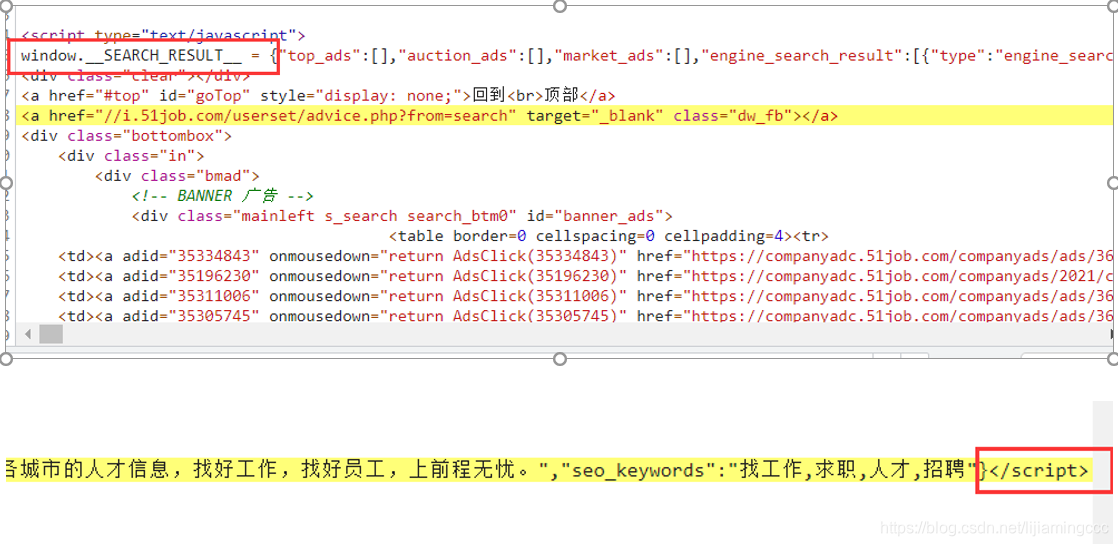
接下来我们要利用正则表达式匹配到两个字符串中间的json数据。新建一个test.py进行测试,提前写好正则表达式,有利于我们提高我们编写scrapy的效率。首先我们将这一行前端代码复制粘贴到我们的代码中,用变量html_str进行存储,如下图所示:
import re
# xxxx是前端中的json数据,数据过长,不易展示
html_str = ' window.__SEARCH_RESULT__ = {"xxxx"}</script> '
# 这里是正则表达式的使用,将想要提取的字符串用(.*?)代替
# 前后分别加上原来相对应的字符即可
json_str = re.findall('window.__SEARCH_RESULT__ = (.*?)</script>', html_str)[0]
# 使用JSON模块 将字符串转化JSON格式的数据
json_dict = json.loads(json_str)
# 查看其中的数据
for i in json_dict['engine_search_result']:
print(i)
5. 代码编写
5.1 start_requests
def start_requests(self):
base_url = "https://search.51job.com/list/200200,000000,0000,00,9,99,%25E5%25A4%25A7%25E6%2595%25B0%25E6%258D%25AE,2,{}.html"
for i in range(1,21):
next_page_url = base_url.format(i)
# print(next_page_url)
# 发送GET请求
yield scrapy.Request(
url=next_page_url,
callback=self.parse
)
5.2 正则提取数据
使用正则表达式提取想要的字符串,并使用json将字符串转换为json字典格式的数据,然后使用循环进入json数据列表中提取其中的数据,找到职位详情页的url地址后,再次进行请求该url,获取更多的职位信息。
def parse(self, response):
# 检查随机请求头是否设置成功
print(response.requests.headers)
html_str = response.text
# . 代表任意一个字符
# ?代表匹配前面的子表达式0到1次
# * 代表匹配前面的子表达式人任意次
json_str = re.findall('window.__SEARCH_RESULT__ = (.*?)</script>', html_str)[0]
json_dict = json.loads(json_str)
for data in json_dict['engine_search_result']:
item = {}
item['job_name'] = data['job_name']
item['company_name'] = data['company_name']
item['job_address'] = data['workarea_text']
item['salary'] = data['providesalary_text']
item['job_time'] = data['updatedate']
# job_need是一个列表
job_need = data['attribute_text']
# join函数将上面的列表转换为字符串
item['job_need'] = ",".join(job_need)
# 提取职位详情页对应的url
job_detail_url = data['job_href']
item['job_detail_url'] = job_detail_url
# 请求职位详情页的url
yield scrapy.Request(
url=job_detail_url,
meta={"item":item},
# 传递给新定义的提取详情页信息的url
callback=self.parse_detail,
)
5.3 提取职位的详情信息
这里详情页信息是非常常规的网页,直接用xpath就可以提取,没有任何反爬机制,同学们可以自行查看详情页信息进行提取
def parse_detail(self,response):
# 将上一步提取的数据,通过meta传递给item
item = response.meta['item']
# 职位详情信息
item["company_detail"] = response.xpath("//div[@class='bmsg job_msg inbox']//p/text()").extract()
yield item

保存文件结果如下:

原文链接:https://blog.csdn.net/lijiamingccc/article/details/119033858
所属网站分类: 技术文章 > 博客
作者:天使是怎样炼成的
链接:http://www.pythonpdf.com/blog/article/448/c4e59a5e4177dc549515/
来源:编程知识网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)