
python爬虫速成
发布于2021-07-25 06:58 阅读(946) 评论(0) 点赞(7) 收藏(3)
前言
注:该项目来源于b站视频Python爬虫编程基础5天速成(2021全新合集)Python入门+数据分析,python语法基础不在本文章中。
python爬虫
1.任务介绍
使用任务驱动型学习方法。任务为爬取电影信息。
需求
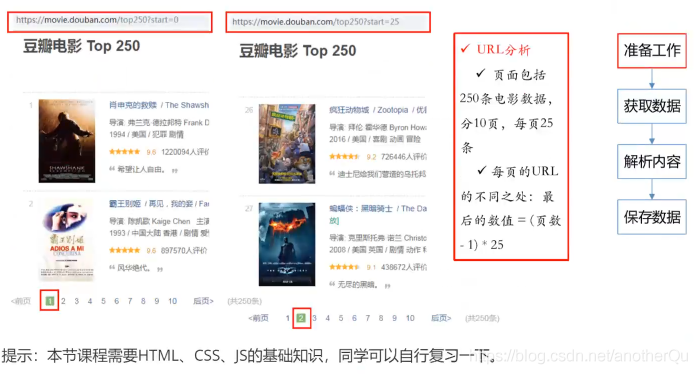
爬取豆瓣电影TOP250的基本信息,包括:
电影名称、豆瓣评分、评价数、电影概述、电影链接等。
2.爬虫初识

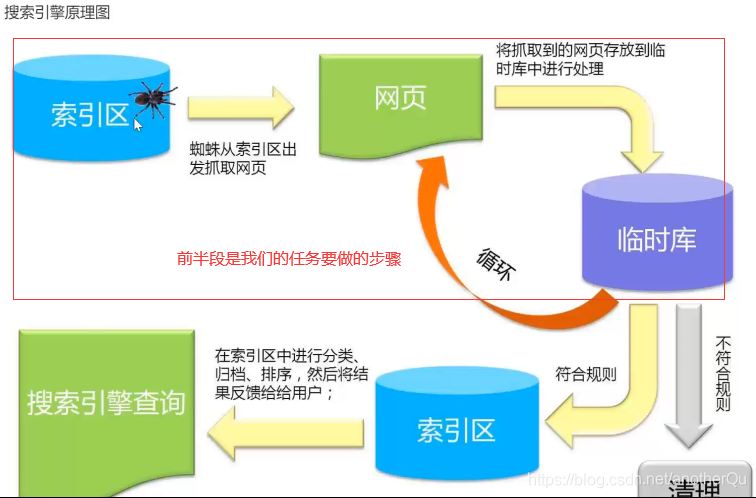
很多网站其实是用的爬虫爬的别的网站的信息,处理后放到数据库里,然后通过自己的前端页面将数据展示出来,通过广告、会员等形式进行流量变现实现盈利。如搜索引擎百度,天眼查,AGE动漫网等等。
搜索引擎原理:
3.基本流程

3.1准备工作
每次发出url请求,其实不是简简单单的就一个网址,还有一些请求头信息,如果要模拟浏览器发出请求,也要带上相应的请求头信息:
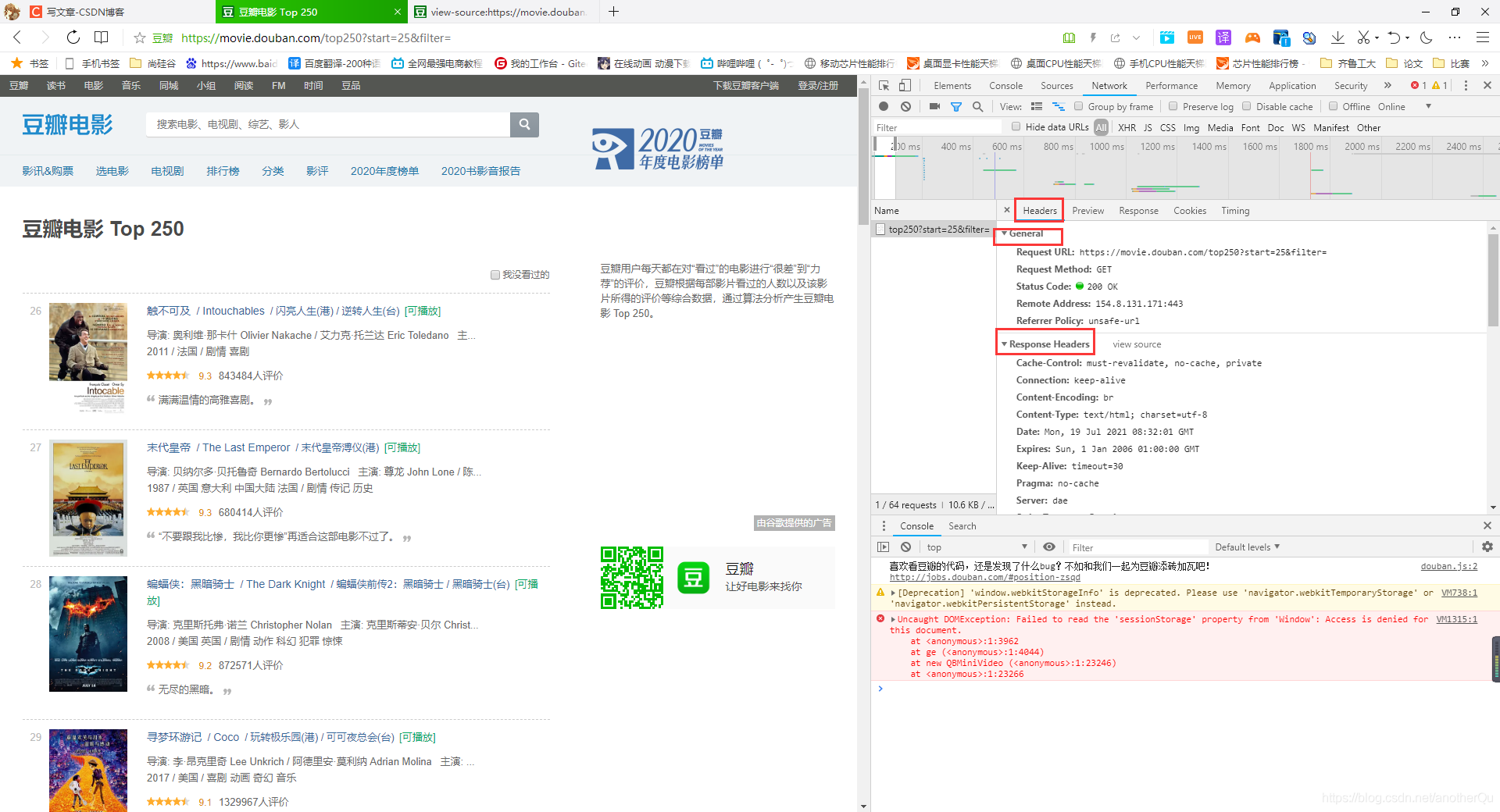
比如想爬取一些登陆后才能看的东西,就一定要记录请求头中的cookie,访问url不带cookie服务器会认为你没有登陆。
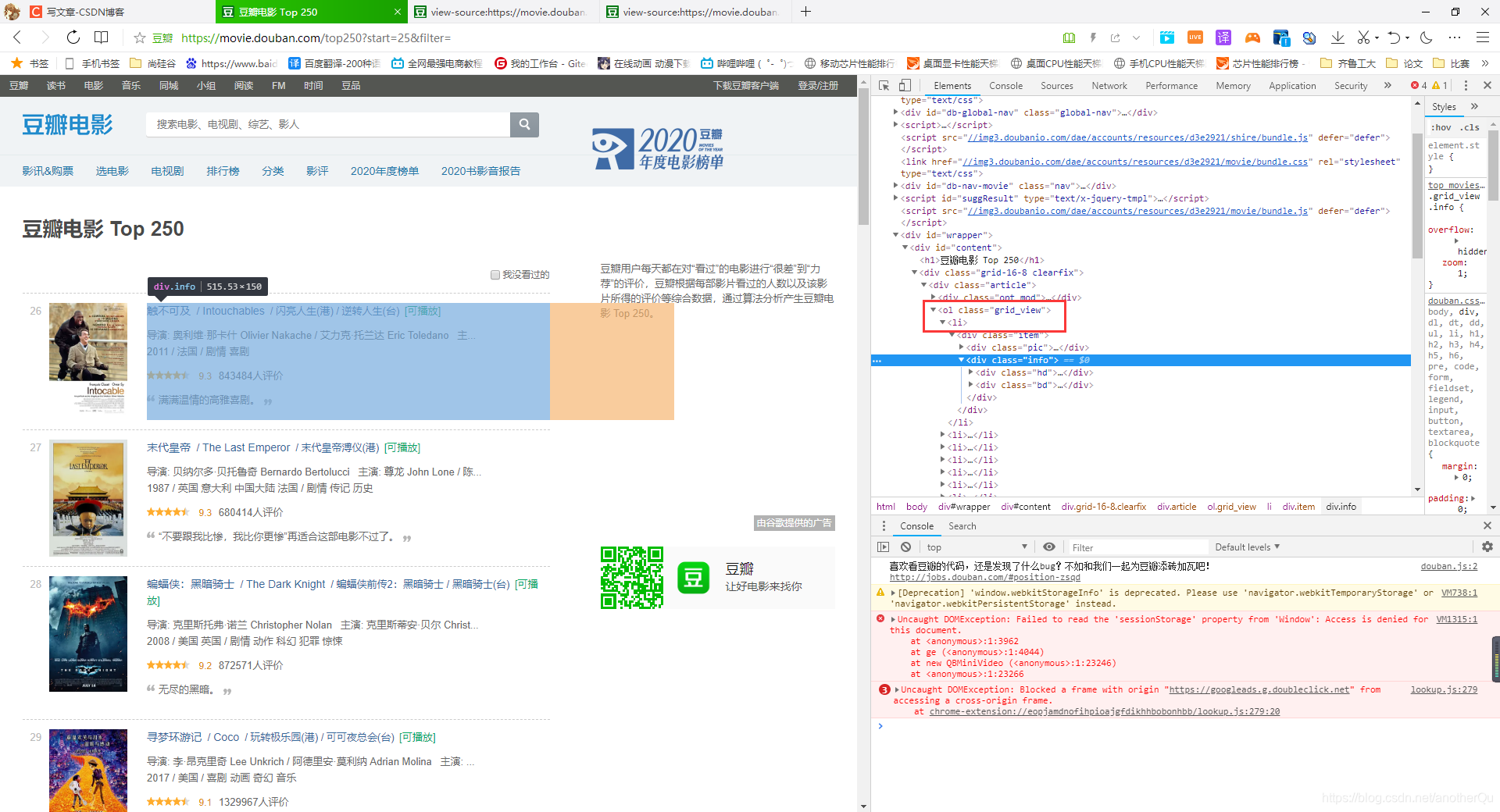
3.1.1分析页面
浏览器页面-右键-检查,在elements下看看数据位置
发现在ol,li列表标签内存在每部电影的数据:
3.1.2编码规范

hello.py:
#-*- coding = utf-8 -*-
#@Time : 2021/7/19 15:22
#@Author : coderhao
#@File : helloword.py
#@Software : PyCharm
# 注释
print("hello world")
使用右键运行:
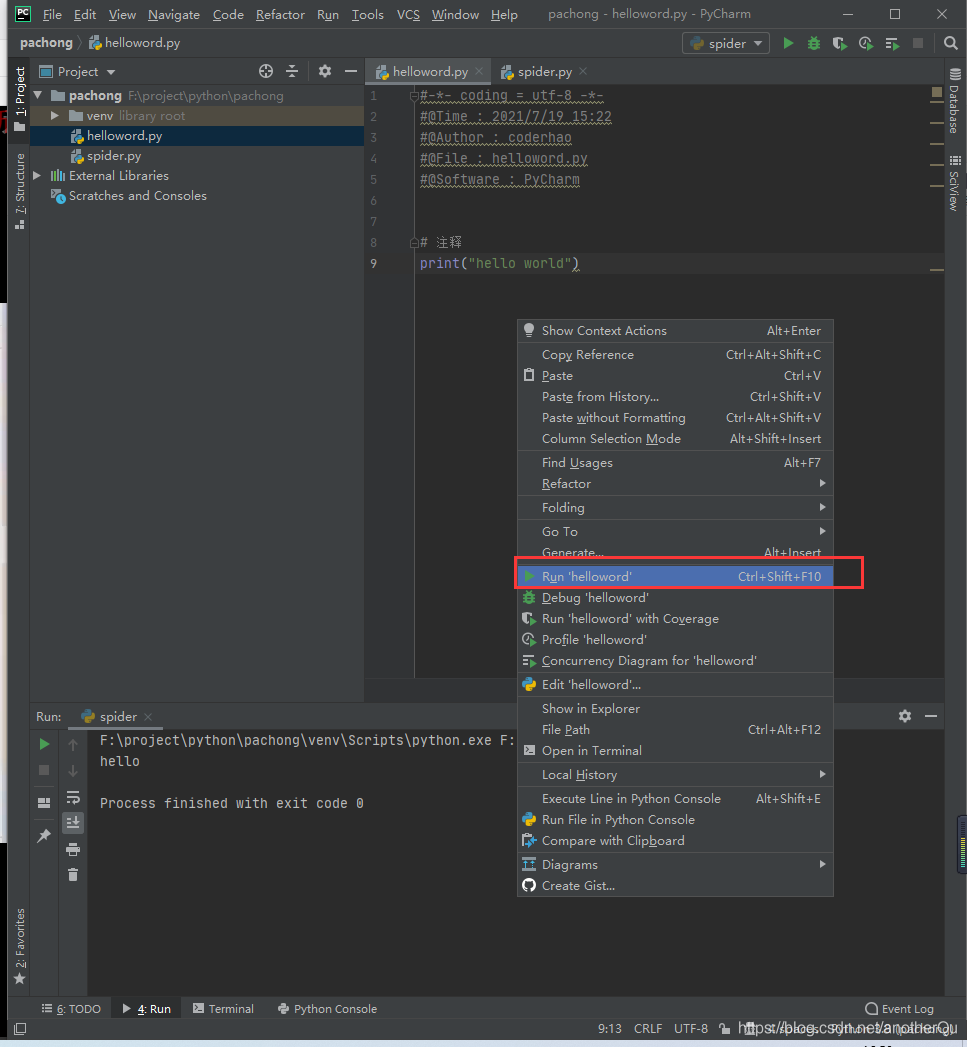
spider.py:
#-*- coding = utf-8 -*-
#@Time : 2021/7/19 16:49
#@Author : coderhao
#@File : spider.py
#@Software : PyCharm
# 定义一个函数
def main():
print("hello")
# 程序执行开始的地方
# 明明像hello.py那样右键就能运行,为什么要这样多此一举呢?
# 因为代码是顺序执行的,可能会出现一些顺序上的问题,因此使用下面的写法,我们来调配函数的调用顺序
# 这样更清楚的明白代码逻辑
if __name__=="__main__":
# 调用函数
main()
3.1.3引入模块

本项目要用的模块:
# 网页解析,获取数据
from bs4 import BeautifulSoup
# 正则表达式,文字匹配
import re
# 制定url,获取网页数据
import urllib.request,urllib.error
# 进行excel操作
import xlwt
# 进行sqlite数据库操作
import sqlite3
在引入的时候,很可能报错,说这模块没有,需要先安装上:
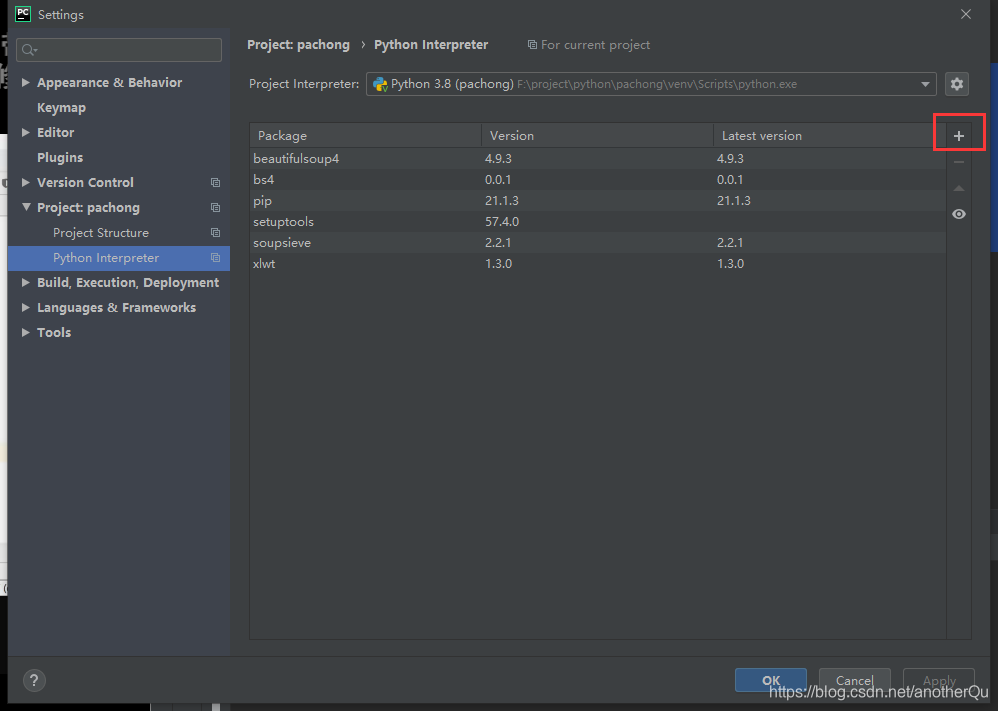
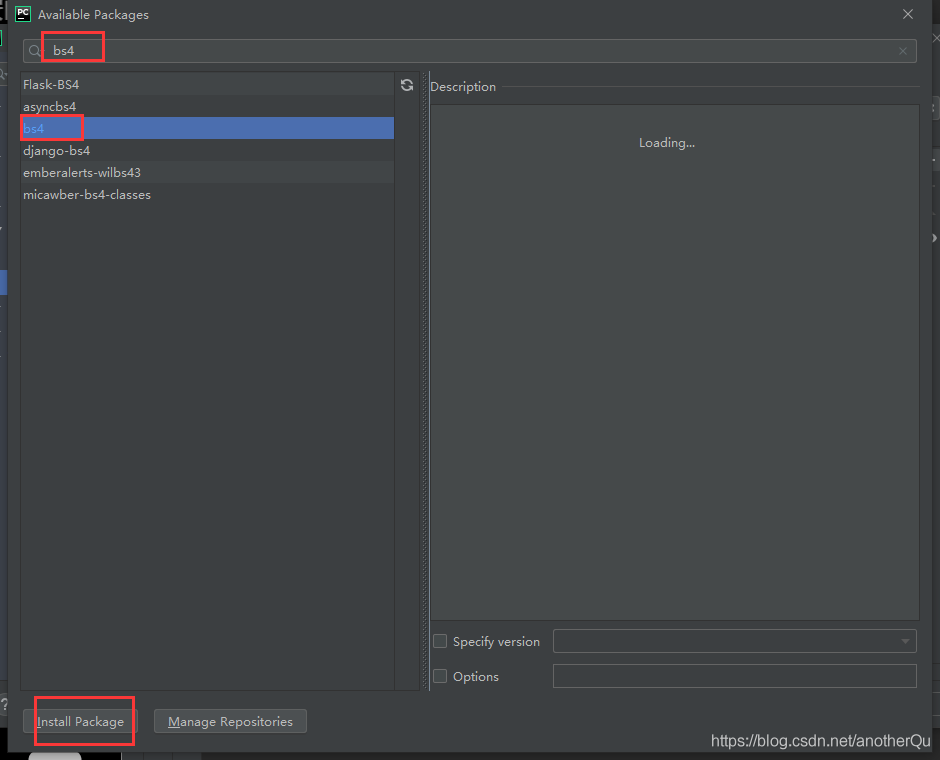
3.1.4完善pachong.py-构建整个流程
pachong.py:
#-*- coding = utf-8 -*-
#@Time : 2021/7/19 17:18
#@Author : coderhao
#@File : pachong.py
#@Software : PyCharm
# 网页解析,获取数据
from bs4 import BeautifulSoup
# 正则表达式,文字匹配
import re
# 制定url,获取网页数据
import urllib.request,urllib.error
# 进行excel操作
import xlwt
# 进行sqlite数据库操作
import sqlite3
def main():
# 访问url
baseurl="https://movie.douban.com/top250?start="
# 保存路径
savepath=".\\doubanTop250.xls"
# 1.爬取网页
datalist=getData(baseurl)
# 3.保存数据
saveData(savepath)
# 1.爬取网页
def getData(baseurl):
datalist=[]
return datalist
# 2.解析数据
# 第一步网页爬取是个循环过程,所以,解析过程也是跟在爬到的每个网页后面的,更恰当地说这一步应该是在第一步内部
# 3.保存数据
def saveData(savepath):
print("todo---save")
if __name__ == '__main__':
main()
3.2获取数据
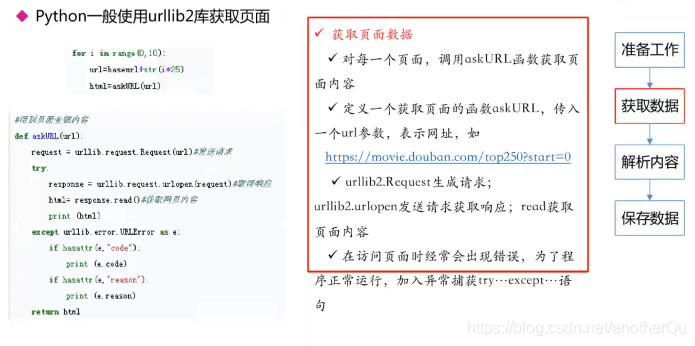
注:python3整合了urllib和urllib2,现在使用urllib就行了
3.2.1介绍urllib
这里用到了一个专门用来简单进行各种网络响应的网站http://httpbin.org/:
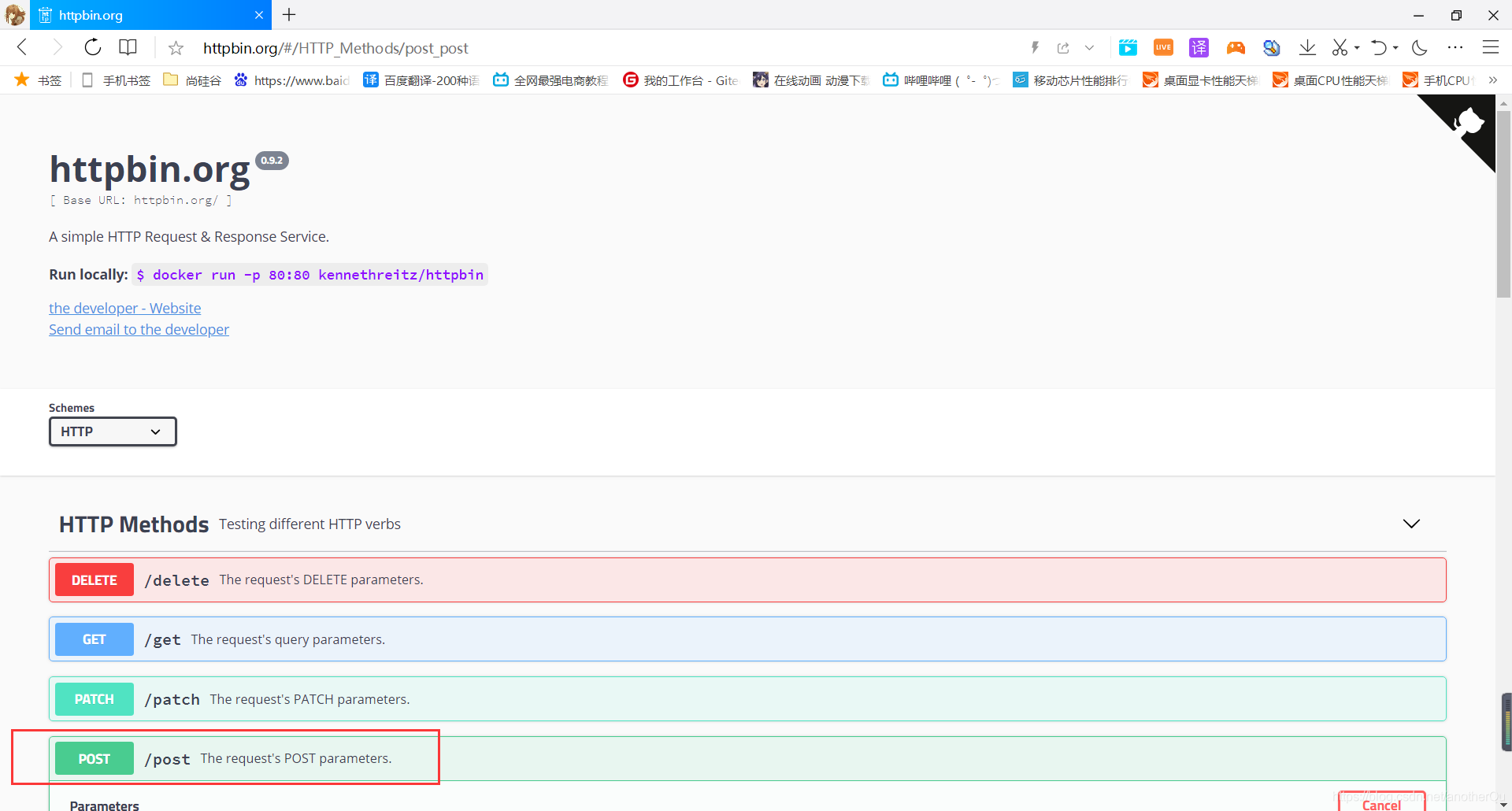


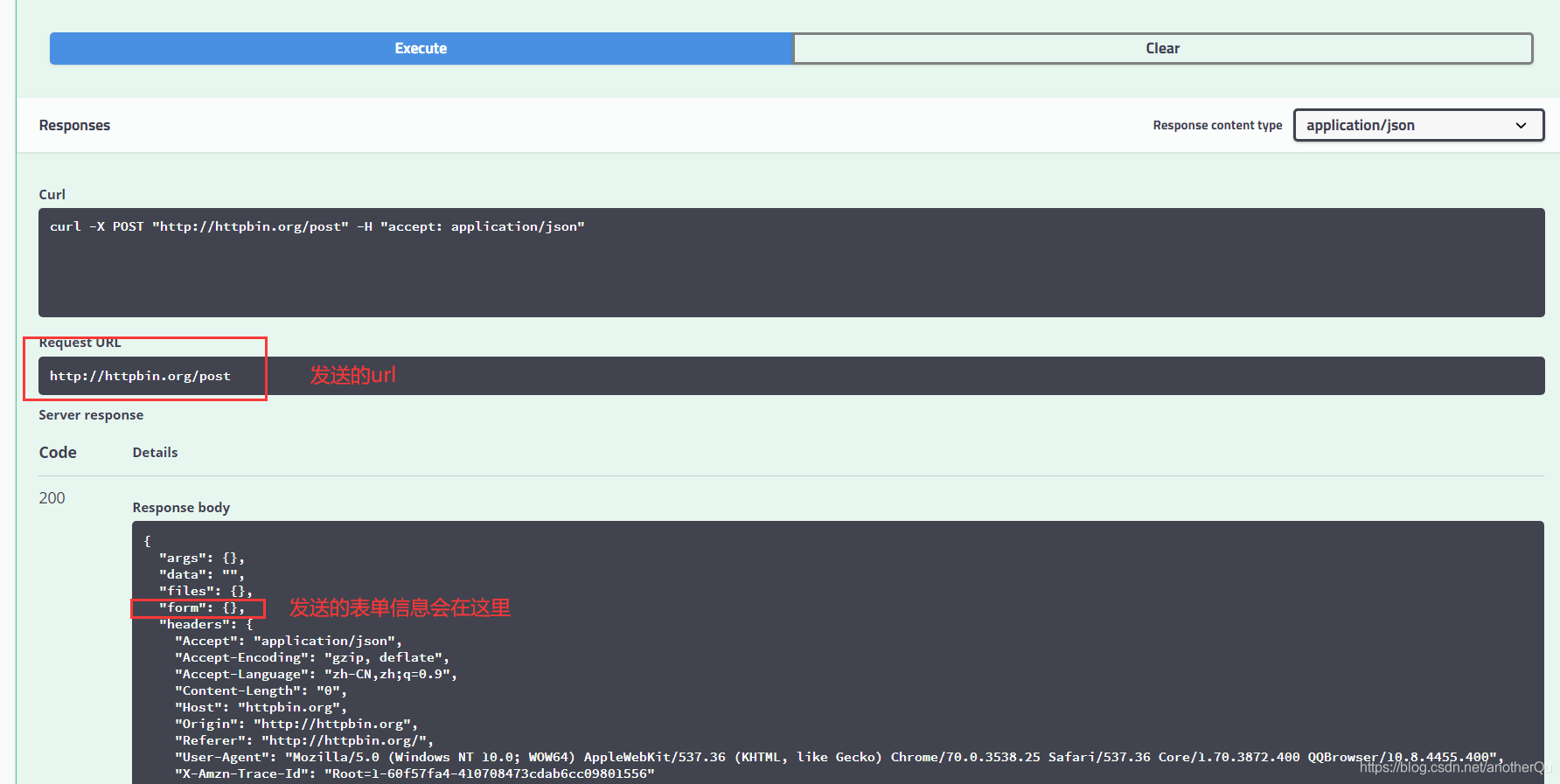
#-*- coding = utf-8 -*-
#@Time : 2021/7/19 20:59
#@Author : coderhao
#@File : testUrllib.py
#@Software : PyCharm
import urllib.request
# 获取一个get请求
response=urllib.request.urlopen("https://www.baidu.com")
# 返回:<http.client.HTTPResponse object at 0x00000163774C03A0>
print(response)
'''
返回:
<html>
<head>
<script>
location.replace(location.href.replace("https://","http://"));
</script>
</head>
<body>
<noscript><meta http-equiv="refresh" content="0;url=http://www.baidu.com/"></noscript>
</body>
</html>
'''
# .read()会默认以二进制方式读取,然后decode('utf-8')会以utf-8的形式解析
# 如果上面url是http这种不带s的不安全方式,打印出的代码会多很多,包含很多其他的东西
print(response.read().decode('utf-8'))
# 获取post请求
# urllib.parse:解析器,将需要模拟post请求发送的键值对按一定格式解析变成二进制然后放到bytes()里
import urllib.parse
# 需要发送的数据变成bytes格式
data=bytes(urllib.parse.urlencode({"hello":"world"}),encoding="utf-8")
response=urllib.request.urlopen("http://httpbin.org/post",data=data)
'''
返回:
{
"args": {},
"data": "",
"files": {},
"form": {
"hello": "world"
},
"headers": {
"Accept-Encoding": "identity",
"Content-Length": "11",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "Python-urllib/3.9",
"X-Amzn-Trace-Id": "Root=1-60f57d96-0d74843b2d2dd55b1669e7cf"
},
"json": null,
"origin": "111.17.194.90",
"url": "http://httpbin.org/post"
}
'''
# 返回的数据和在httpbin.org上看到的一致
print(response.read().decode('utf-8'))
# 使用get请求测试超时情况
# 正常时
response=urllib.request.urlopen("http://httpbin.org/get")
'''
返回:
{
"args": {},
"headers": {
"Accept-Encoding": "identity",
"Host": "httpbin.org",
"User-Agent": "Python-urllib/3.9",
"X-Amzn-Trace-Id": "Root=1-60f580e9-110d8eb460884b5a3e13eb7e"
},
"origin": "111.17.194.90",
"url": "http://httpbin.org/get"
}
'''
# 通过返回数据中的 "User-Agent":"Python-urllib/3.9" 可以发现服务器察觉到了我们是python程序,即爬虫,而不是真正的浏览器
# 在访问反爬虫的服务器时需要进行伪装,不然极有可能ip锁定无法访问
print(response.read().decode('utf-8'))
# 超时
request=urllib.request.urlopen("http://httpbin.org/get",timeout=0.01)
# 超时报错误: urllib.error.URLError: <urlopen error timed out>
print(request.read().decode('utf-8'))
# 所以防止超时异常这种情况需要捕捉异常
# 正常情况下,由于url失效、网络不畅、服务器繁忙、服务器拒绝等等情况导致访问长时间无应答是很普遍的,因此捕获异常,放过去,之后再返回来针对性的爬才是正确的方式
try:
response = urllib.request.urlopen("http://httpbin.org/get", timeout=0.01)
print(response.read().decode('utf-8'))
except urllib.error.URLError as e:
print("time out!")
response = urllib.request.urlopen("http://httpbin.org/get")
# 状态码:200
# 尝试爬豆瓣网发现返回为错误代码418,意思是服务器发现是个爬虫
print(response.status)
# 得到响应头信息,一个数组
print(response.getheaders())
# 得到某个特定的响应头信息
print(response.getheader("Date"))
# 对于爬虫程序伪装的问题,前面的请求方式和浏览器最大的区别就是前面的方式只发url,而浏览器除了发url还发一些头信息
# headers里放伪装信息,F12-Network-All-Headers-Request Headers里面的都可以放
# 这里headers里放入了最重要的User-Agent,用户代理,表示我们是个xxx规格的浏览器,
url ="http://httpbin.org/post"
data=bytes(urllib.parse.urlencode({"hello":"world"}),encoding="utf-8")
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3872.400 QQBrowser/10.8.4455.400"
}
request=urllib.request.Request(url,data=data,headers=headers,method="POST")
response=urllib.request.urlopen(request)
'''
返回:
{
"args": {},
"data": "",
"files": {},
"form": {
"hello": "world"
},
"headers": {
"Accept-Encoding": "identity",
"Content-Length": "11",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3872.400 QQBrowser/10.8.4455.400",
"X-Amzn-Trace-Id": "Root=1-60f58c8b-4e8c004a2cdca535024c38ed"
},
"json": null,
"origin": "111.17.194.90",
"url": "http://httpbin.org/post"
}
'''
# 这里返回的响应头中的User-Agent就是浏览器信息了,服务器没识别到爬虫
print(response.read().decode('utf-8'))
# get方式请求豆瓣网试试
url ="https://www.douban.com"
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3872.400 QQBrowser/10.8.4455.400"
}
request=urllib.request.Request(url,headers=headers)
response=urllib.request.urlopen(request)
# 得到了豆瓣的相应信息,由于信息太多,这里不再用多行注释展开
print(response.read().decode('utf-8'))
3.2.2完善pachong.py-获取数据
有了3.2.1中对urllib的使用,我们就可以对pachong.py中获取数据部分进行完善。
pachong.py(main方法完善了爬取网页;其他方法添加了一个爬取特定url的小方法):
#-*- coding = utf-8 -*-
#@Time : 2021/7/19 17:18
#@Author : coderhao
#@File : pachong.py
#@Software : PyCharm
# 网页解析,获取数据
from bs4 import BeautifulSoup
# 正则表达式,文字匹配
import re
# 制定url,获取网页数据
import urllib.request,urllib.error
# 进行excel操作
import xlwt
# 进行sqlite数据库操作
import sqlite3
def main():
# 访问url
baseurl="https://movie.douban.com/top250?start="
# 保存路径
savepath=".\\doubanTop250.xls"
# 1.爬取网页
datalist=getData(baseurl)
# 3.保存数据
saveData(savepath)
askURL(baseurl)
# 1.爬取网页
def getData(baseurl):
datalist=[]
# 通过循环得到所有的url
# range函数左闭右开
for i in range(0,10):
url=baseurl+str(i*25)
html=askURL(url)
# 2.解析数据
# 第一步网页爬取是个循环过程,所以,解析过程也是跟在爬到的每个网页后面的,更恰当地说这一步应该是在第一步内部
# 将html解析后的信息加入到datalist中
datalist.append()
return datalist
# 3.保存数据
def saveData(savepath):
print("todo---save")
# 其他单独方法
# 得到一个指定url内容的方法
def askURL(url):
html=""
# 模拟浏览器请求头信息
head={
# 用户代理,告诉服务器我们是什么类型的机器/浏览器,本质是告诉服务器我们能接收什么水平的文件
# 从浏览器F12里复制时请尽量让该信息在一行里显示再赋值,不然复制过来也是多行而且数据中间有很多空格,有可能出问题
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3870.400 QQBrowser/10.8.4405.400"
}
# 模拟的总请求信息
request = urllib.request.Request(url, headers=head)
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
# 可以输出测试
# print(html)
except urllib.error.URLError as e:
# 如果e有code,打印code
if hasattr(e,"code"):
print(e.code)
# 如果e有reason,打印reason
if hasattr(e,"reason"):
print(e.reason)
return html
if __name__ == '__main__':
main()
3.3解析内容

3.3.1BeautifulSoup的使用
首先需要一个html网页作为测试对象,打开baidu,ctrl+s保存为html文件,放到和testBs4.py并列的位置,更名为baidu,调格式可以ctrl+alt+L。
这里做测试的网页样子:
目录结构:
testBs4.py:
#-*- coding = utf-8 -*-
#@Time : 2021/7/20 9:58
#@Author : coderhao
#@File : testBs4.py
#@Software : PyCharm
'''
BeautifulSoup4将复杂HTML文档转换成一个复杂的树形结构,每个节点都是python对象,所有对象可以归纳为四种:
- Tag 标签及其内容
- NavigableString 标签内部内容,就是字符串
- BeautifulSoup
- Comment
'''
from bs4 import BeautifulSoup
# 打开文件路径
file=open("./baidu.html","rb")
# 文件读到内存中
html=file.read()
# 参数表示(解析哪个内容,使用BeautifulSoup中解析什么文件格式的解析器),这里参数为(html,"html.parser")。
bs=BeautifulSoup(html,"html.parser")
# <title>百度一下,你就知道</title>
# 抽取的就是baidu.html中的title标签
# 再说的直接一点,bs.xx,抽取的就是html中第一个xx标签的内容(带标签)
print(bs.title)
# <class 'bs4.element.Tag'>
print(type(bs.title))
# 不带标签,只要内容
# 如果内容带有注释,则type(bs.title.string)是bs4.element.Comment格式,print会输出不包含注释符号的字符串
# 百度一下,你就知道
print(bs.title.string)
# <class 'bs4.element.NavigableString'>
print(type(bs.title.string))
# 获取某一标签的所有属性,返回一个字典
# {'href': 'http://news.baidu.com', 'target': '_blank', 'class': ['mnav', 'c-font-normal', 'c-color-t']}
print(bs.a.attrs)
# <class 'dict'>
print(type(bs.a.attrs))
# 整个文档
print(bs)
# <class 'bs4.BeautifulSoup'>
print(type(bs))
#————————————————————————————————————————————————————
# 以上为基本用法,但用起来效率太低,下面说怎么应用
# 一、文档的遍历(不常用):将文档中相似的东西遍历出来
# 详细的遍历文档树网址:https://blog.csdn.net/chinaltx/article/details/86748763
# 其中如下:
# 得到head标签内部的所有内容,以列表形式得到
print(bs.head.contents)
# 列表中下标为1的元素
print(bs.head.contents[1])
# 二、文档的搜索(常用):有针对性的根据结构取出数据
# 1.find_all()搜索符合特定条件的所有标签,以列表方式返回
# 1.1查找所有a标签的内容,以列表形式返回
t_list=bs.find_all("a")
# 1.2正则表达式搜索,使用search()方法来匹配内容
# 例:查找标签中含有a字符的内容,以列表形式返回
import re
t_list=bs.find_all(re.compile("a"))
# 1.3传入一个函数/方法,根据函数的要求来搜索
# 方法:传入一个标签,判断标签里面是否存在name属性
def name_is_exists(tag):
return tag.has_attr("name")
# 查找标签中含有name属性的内容,以列表形式返回
t_list=bs.find_all(name_is_exists)
# 以循环方式输出查看
# for item in t_list:
# print("---------------------------------------------")
# print(item)
# 2.kwargs 参数搜索
# 搜索标签属性符合规则的标签内容
t_list=bs.find_all(id="head")
# 搜索存在某个标签属性的标签
t_list=bs.find_all(class_=True)
# 3.text参数
'''
---------------------------------------------
新闻
---------------------------------------------
地图
---------------------------------------------
直播
---------------------------------------------
地图
'''
# 搜索标签内容,条件是text中内容=标签内容
t_list=bs.find_all(text=["新闻","地图","直播"])
# 看起来这个搜索好像在做无用功,我知道标签内容还用你搜?但其实是可以配合正则表达式来搜索含有某些特性的标签内容的
# 搜索含有数字的标签内容
t_list=bs.find_all(text=re.compile("\d"))
# 4.limit参数
# 限制搜索的数量
t_list=bs.find_all("a",limit=3)
# 5.css选择器
# 通过标签查找
t_list=bs.select("title")
# 通过标签里面的属性查找
t_list=bs.select("a[class='share-icons-tqq']")
# 通过类名查找:.xxx表示类名
t_list=bs.select(".mnav")
# 通过id查找:#xx表示id
t_list=bs.select("#u1")
# t_list拿到文本的方式
print(t_list[0].get_text())
3.3.2正则表达式的补充
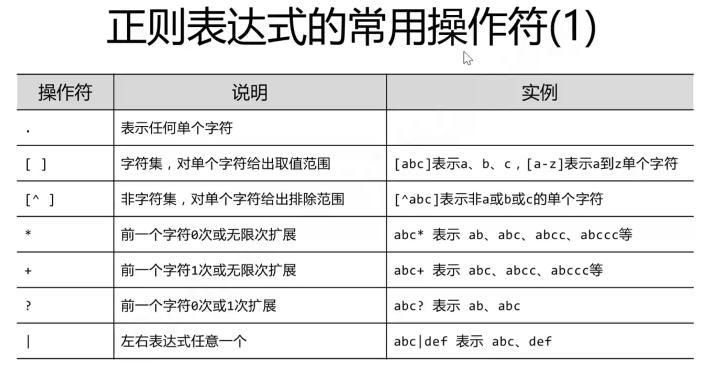
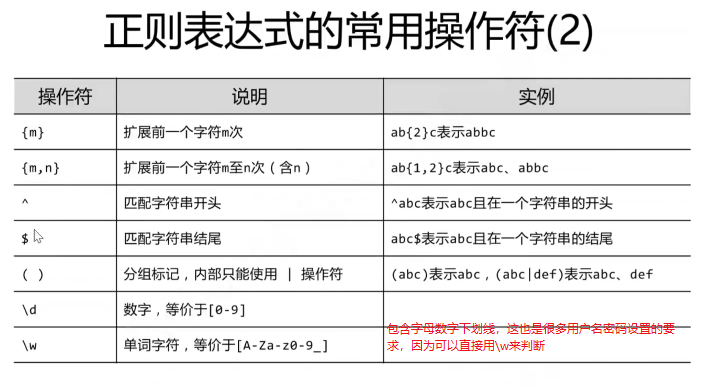
以上是正则表达式的规范模板,在不同的语言中有不同的解决正则表达式匹配的库。
比如python中就是re库:

还有一些模式设置:

testRe.py:
#-*- coding = utf-8 -*-
#@Time : 2021/7/21 10:26
#@Author : coderhao
#@File : testRe.py
#@Software : PyCharm
# 正则表达式:字符串模式(判断字符串是否符合一定的标准)
# 引入re
import re
# 1.有模式对象
# 创建模式对象
# 此处的AA是正则表达式,用来验证其它字符串
pat=re.compile(".*a")
# 验证字符串bra是否符合.*a
# <re.Match object; span=(0, 3), match='bra'> :在0-2下标序列的位置匹配到(左闭右开)
m=pat.search("bra")
print(m)
# 结果为None,未匹配上
m=pat.search("bed")
print(m)
# 2.没有模式对象,简写,前面是模板,后面是被校验对象
m=re.search(".*a","bed")
print(m)
# 找到所有符合的然后以列表形式返回
m=re.findall("a","sajlkfjaf")
# ['a', 'a']
print(m)
m=re.findall("[A-Z]","ADASasoJKLlajdaS")
# ['A', 'D', 'A', 'S', 'J', 'K', 'L', 'S']
print(m)
m=re.findall("[A-Z]+","ADASasoJKLlajdaS")
# ['ADAS', 'JKL', 'S']
print(m)
# sub,替换作用
# 将"a;ljfds;fsaj"中所有a替换为A
m=re.sub("a","A","a;ljfds;fsaj")
print(m)
# 建议在正则表达式中,被比较的字符串前面加上r,防止转义字符干扰
str="\adsjalkd\'ad"
# dsjalkd'ad
print(str)
str=r"\adsjalkd\'ad"
# \adsjalkd\'ad
print(str)
3.3.3完善pachong.py-正则提取
对每次遍历得到的html进行正则提取。
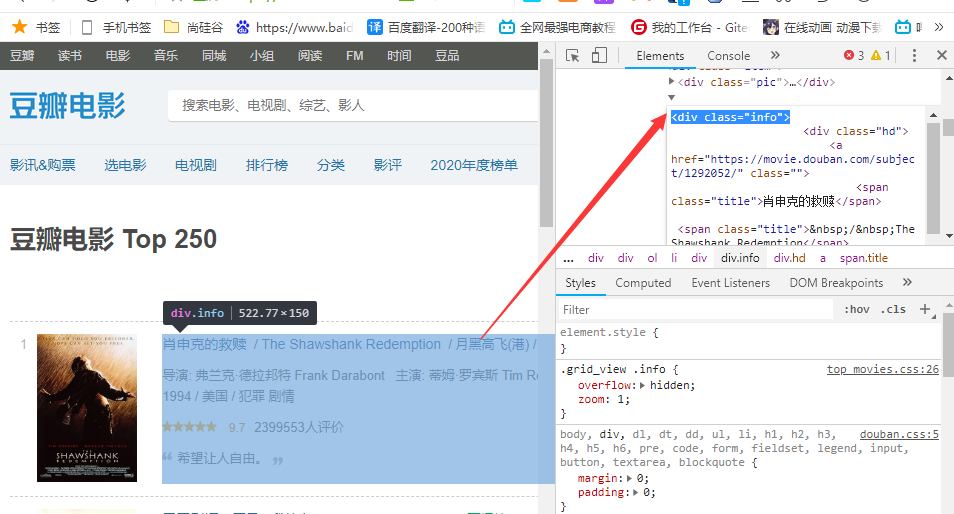
pachong.py:
# -*- coding = utf-8 -*-
# @Time : 2021/7/19 17:18
# @Author : coderhao
# @File : pachong.py
# @Software : PyCharm
# 网页解析,获取数据
from bs4 import BeautifulSoup
# 正则表达式,文字匹配
import re
# 制定url,获取网页数据
import urllib.request, urllib.error
# 进行excel操作
import xlwt
# 进行sqlite数据库操作
import sqlite3
def main():
# 访问url
baseurl = "https://movie.douban.com/top250?start="
# 保存路径
savepath = ".\\doubanTop250.xls"
# 1.爬取网页
datalist = getData(baseurl)
# 3.保存数据
saveData(savepath)
# 全局变量
# re.compile()创建正则规则
'''
对照规则:
<div class="item">
<div class="pic">
<em class="">1</em>
<a href="https://movie.douban.com/subject/1292052/">
<img alt="肖申克的救赎" class="" src="https://img2.doubanio.com/view/photo/s_ratio_poster/public/p480747492.jpg" width="100"/>
</a>
</div>
<div class="info">
<div class="hd">
<a class="" href="https://movie.douban.com/subject/1292052/">
<span class="title">肖申克的救赎</span>
<span class="title"> / The Shawshank Redemption</span>
<span class="other"> / 月黑高飞(港) / 刺激1995(台)</span>
</a>
<span class="playable">[可播放]</span>
</div>
<div class="bd">
<p class="">
导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...<br/>
1994 / 美国 / 犯罪 剧情
</p>
<div class="star">
<span class="rating5-t"></span>
<span class="rating_num" property="v:average">9.7</span>
<span content="10.0" property="v:best"></span>
<span>2399691人评价</span>
</div>
<p class="quote">
<span class="inq">希望让人自由。</span>
</p>
</div>
</div>
</div>
'''
findlink = re.compile(r'a href="(.*?)">')
# re.S忽略换行符
# findImgSrc=re.compile(r'<img.*src="(.*?)" width="100"/>',re.S)
findImgSrc = re.compile(r'<img alt=".*" class="" src="(.*?)" width="100"/>', re.S)
findTitle = re.compile(r'<span class="title">(.*?)</span>')
findRating = re.compile(r'<span class="rating_num" property="v:average">(.*?)</span>')
findJudge = re.compile(r'<span>(\d*?)人评价</span>')
findInq = re.compile(r'<span class="inq">(.*?)</span>')
findBd = re.compile(r'<p class="">(.*?)</p>', re.S)
# 1.爬取网页
def getData(baseurl):
datalist = []
# 通过循环得到所有的url
# range函数左闭右开
for i in range(0, 10):
url = baseurl + str(i * 25)
html = askURL(url)
# 2.解析数据
# 第一步网页爬取是个循环过程,所以,解析过程也是跟在爬到的每个网页后面的,更恰当地说这一步应该是在第一步内部
# 解析器选择,并解析
soup = BeautifulSoup(html, "html.parser")
# 遍历符合要求的字符串,形成列表。需要的是<div class="info">的内部内容
for item in soup.find_all("div", class_="item"):
# item存的一个电影的信息
# print(item)
# 用来保存一部电影的所有信息
data = []
item = str(item)
# 影片详情链接
link = re.findall(findlink, item)[0]
print("link:" + link)
data.append(link)
# 影片图片url
imgSrc = re.findall(findImgSrc, item)[0]
print("imgSrc:" + imgSrc)
data.append(imgSrc)
# 影片题目
title = re.findall(findTitle, item)
if (len(title) == 2):
# 中文名
ctitle = title[0]
# 外文名
otitle = title[1].replace("/", "") # 去掉/
data.append(ctitle)
data.append(otitle)
else:
data.append(title[0])
data.append(' ') # 留空
print("ctitle:" + ctitle + "otitle:" + otitle)
# 影片评分
rating = re.findall(findRating, item)[0]
print("rating:" + rating)
data.append(rating)
# 评分人数
judge = re.findall(findJudge, item)[0]
print("judge:" + judge)
data.append(judge)
# 影片简述
inq = re.findall(findInq, item)
if (len(inq) != 0):
inq = inq[0].replace("。", "")
data.append(inq)
else:
data.append(" ")
inq = " "
print("inq:" + inq)
# 影片导演、主演、年份、国家、类型
bd = re.findall(findBd, item)[0]
bd = re.sub('<br(\s+)?/>(\s+)?', " ", bd)
bd = re.sub('/', " ", bd)
data.append(bd.strip()) # bd.strip()去空格
print("bd:" + bd)
# 使用一个影片测试的时候,可以放开break
# break
# 将html解析后的信息加入到datalist中
datalist.append(data)
return datalist
# 3.保存数据
def saveData(savepath):
print("todo---save")
# 其他单独方法
# 得到一个指定url内容的方法
def askURL(url):
html = ""
# 模拟浏览器请求头信息
head = {
# 用户代理,告诉服务器我们是什么类型的机器/浏览器,本质是告诉服务器我们能接收什么水平的文件
# 从浏览器F12里复制时请尽量让该信息在一行里显示再赋值,不然复制过来也是多行而且数据中间有很多空格,有可能出问题
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3870.400 QQBrowser/10.8.4405.400"
}
# 模拟的总请求信息
request = urllib.request.Request(url, headers=head)
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
# 可以输出测试
# print(html)
except urllib.error.URLError as e:
# 如果e有code,打印code
if hasattr(e, "code"):
print(e.code)
# 如果e有reason,打印reason
if hasattr(e, "reason"):
print(e.reason)
return html
if __name__ == '__main__':
main()
打断点可以看到查到了250条记录并存到了datalist里:
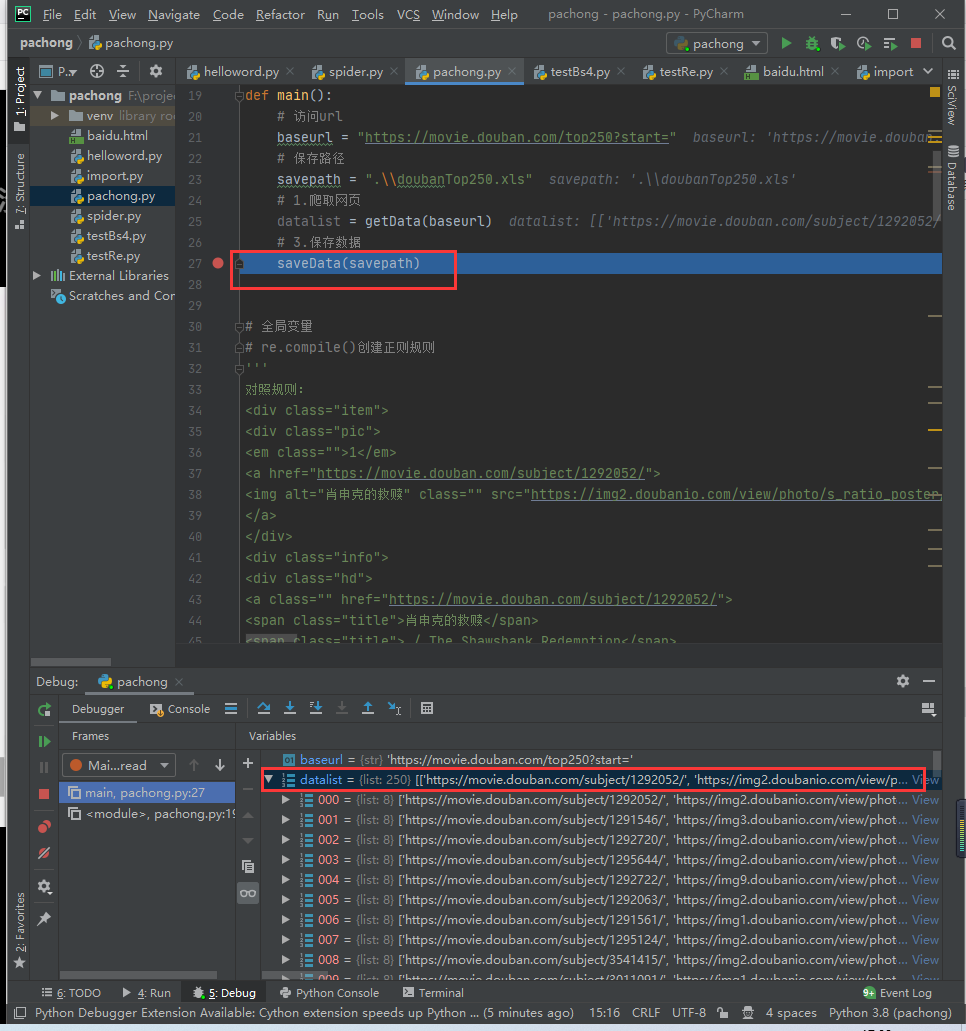
3.4保存数据
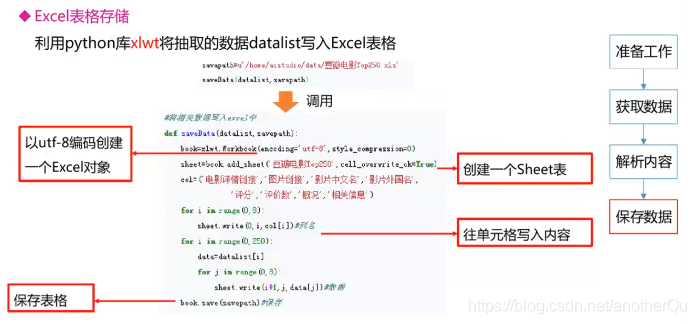
3.4.1保存到excel中
小试一下:
testXwlt.py:
# -*- coding = utf-8 -*-
# @Time : 2021/7/21 17:15
# @Author : coderhao
# @File : testXwlt.py
# @Software : PyCharm
import xlwt
# 创建workbook对象,最后会对应成一个.xls
workbook = xlwt.Workbook(encoding="utf-8")
# 创建worksheet对象,最后会对应成xls里面的一个sheet
worksheet = workbook.add_sheet("sheet1")
# 写入数据,在坐标(0,0)上写入hello
worksheet.write(0, 0, "hello")
# 持久化xls
workbook.save("student.xls")
小例子,99乘法表:
99chengfabiao.py:
#-*- coding = utf-8 -*-
#@Time : 2021/7/21 19:23
#@Author : coderhao
#@File : 99chengfabiao.py
#@Software : PyCharm
import xlwt
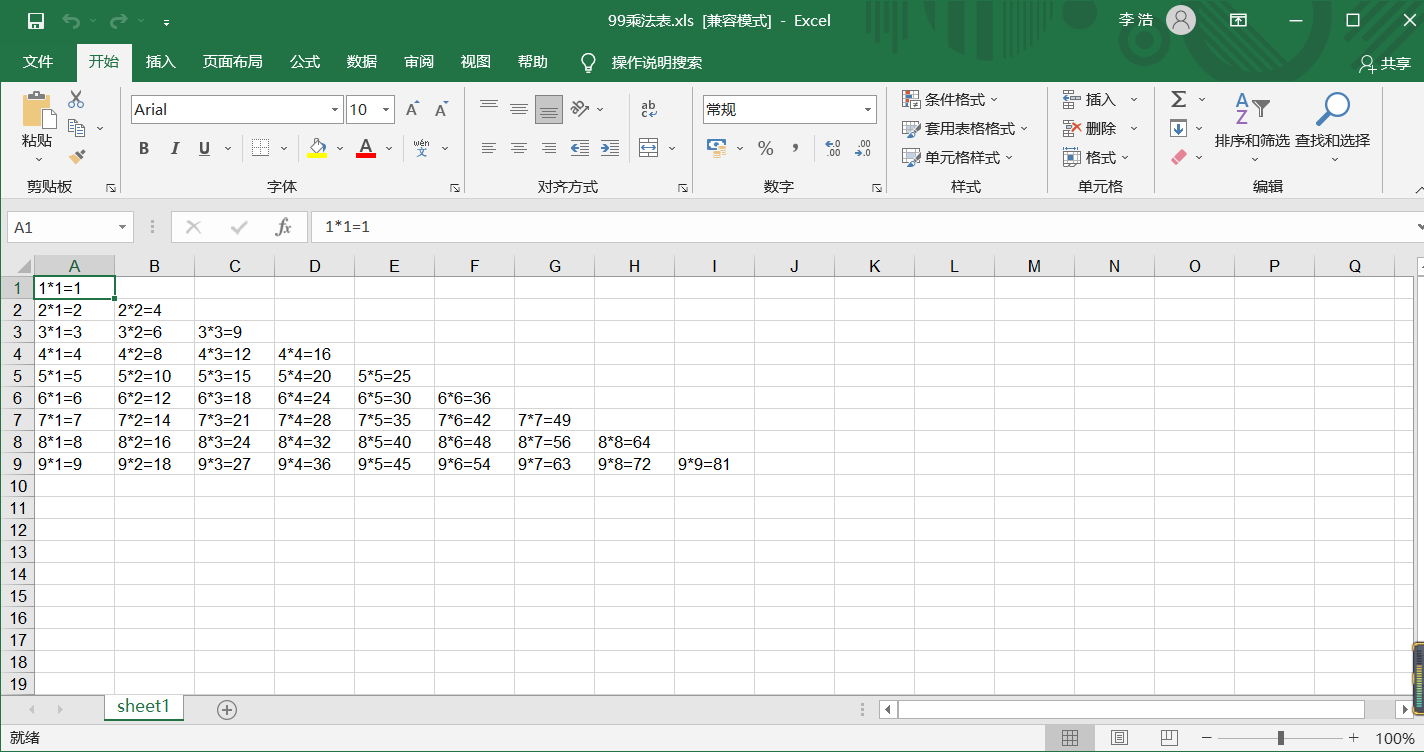
# 案例:在xls里保存99乘法表
def sav99():
# 创建workbook对象,最后会对应成一个.xls
workbook = xlwt.Workbook(encoding="utf-8")
# 创建worksheet对象,最后会对应成xls里面的一个sheet
worksheet = workbook.add_sheet("sheet1")
# i:1--9
for i in range(1, 10):
# j:1--i
for j in range(1, i + 1):
result = "%d*%d=%d" % (i, j, i * j)
# print(result)
worksheet.write(i - 1, j - 1, result)
workbook.save("99乘法表.xls")
if __name__ == '__main__':
sav99()
99乘法表.xls:
3.4.2完善pachong.py-数据持久化到xls中
# -*- coding = utf-8 -*-
# @Time : 2021/7/19 17:18
# @Author : coderhao
# @File : pachong.py
# @Software : PyCharm
# 网页解析,获取数据
from bs4 import BeautifulSoup
# 正则表达式,文字匹配
import re
# 制定url,获取网页数据
import urllib.request, urllib.error
# 进行excel操作
import xlwt
# 进行sqlite数据库操作
import sqlite3
def main():
# 访问url
baseurl = "https://movie.douban.com/top250?start="
# 保存路径
savepath = "doubanTop250.xls"
# 1.爬取网页
datalist = getData(baseurl)
# 3.保存数据
saveData(savepath, datalist)
# 全局变量
# re.compile()创建正则规则
'''
对照规则:
<div class="item">
<div class="pic">
<em class="">1</em>
<a href="https://movie.douban.com/subject/1292052/">
<img alt="肖申克的救赎" class="" src="https://img2.doubanio.com/view/photo/s_ratio_poster/public/p480747492.jpg" width="100"/>
</a>
</div>
<div class="info">
<div class="hd">
<a class="" href="https://movie.douban.com/subject/1292052/">
<span class="title">肖申克的救赎</span>
<span class="title"> / The Shawshank Redemption</span>
<span class="other"> / 月黑高飞(港) / 刺激1995(台)</span>
</a>
<span class="playable">[可播放]</span>
</div>
<div class="bd">
<p class="">
导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...<br/>
1994 / 美国 / 犯罪 剧情
</p>
<div class="star">
<span class="rating5-t"></span>
<span class="rating_num" property="v:average">9.7</span>
<span content="10.0" property="v:best"></span>
<span>2399691人评价</span>
</div>
<p class="quote">
<span class="inq">希望让人自由。</span>
</p>
</div>
</div>
</div>
'''
findlink = re.compile(r'a href="(.*?)">')
# re.S忽略换行符
# findImgSrc=re.compile(r'<img.*src="(.*?)" width="100"/>',re.S)
findImgSrc = re.compile(r'<img alt=".*" class="" src="(.*?)" width="100"/>', re.S)
findTitle = re.compile(r'<span class="title">(.*?)</span>')
findRating = re.compile(r'<span class="rating_num" property="v:average">(.*?)</span>')
findJudge = re.compile(r'<span>(\d*?)人评价</span>')
findInq = re.compile(r'<span class="inq">(.*?)</span>')
findBd = re.compile(r'<p class="">(.*?)</p>', re.S)
# 1.爬取网页
def getData(baseurl):
print("start:getData()")
datalist = []
# 通过循环得到所有的url
# range函数左闭右开
for i in range(0, 10):
url = baseurl + str(i * 25)
html = askURL(url)
# 2.解析数据
# 第一步网页爬取是个循环过程,所以,解析过程也是跟在爬到的每个网页后面的,更恰当地说这一步应该是在第一步内部
# 解析器选择,并解析
soup = BeautifulSoup(html, "html.parser")
# 遍历符合要求的字符串,形成列表。需要的是<div class="info">的内部内容
for item in soup.find_all("div", class_="item"):
# item存的一个电影的信息
# print(item)
# 用来保存一部电影的所有信息
data = []
item = str(item)
# 影片详情链接
link = re.findall(findlink, item)[0]
# print("link:" + link)
data.append(link)
# 影片图片url
imgSrc = re.findall(findImgSrc, item)[0]
# print("imgSrc:" + imgSrc)
data.append(imgSrc)
# 影片题目
title = re.findall(findTitle, item)
if (len(title) == 2):
# 中文名
ctitle = title[0]
# 外文名
otitle = title[1].replace("/", "") # 去掉/
data.append(ctitle)
data.append(otitle)
else:
data.append(title[0])
data.append(' ') # 留空
# print("ctitle:" + ctitle + "otitle:" + otitle)
# 影片评分
rating = re.findall(findRating, item)[0]
# print("rating:" + rating)
data.append(rating)
# 评分人数
judge = re.findall(findJudge, item)[0]
# print("judge:" + judge)
data.append(judge)
# 影片简述
inq = re.findall(findInq, item)
if (len(inq) != 0):
inq = inq[0].replace("。", "")
data.append(inq)
else:
data.append(" ")
inq = " "
# print("inq:" + inq)
# 影片导演、主演、年份、国家、类型
bd = re.findall(findBd, item)[0]
bd = re.sub('<br(\s+)?/>(\s+)?', " ", bd)
bd = re.sub('/', " ", bd)
data.append(bd.strip()) # bd.strip()去空格
# print("bd:" + bd)
# 使用一个影片测试的时候,可以放开break
# break
# 将html解析后的信息加入到datalist中
datalist.append(data)
print("finished:getData()")
return datalist
# 3.保存数据
def saveData(savepath, datalist):
print("start:saveData()")
# 创建workbook对象,最后会对应成一个.xls。style_compression=0:样式压缩
workbook = xlwt.Workbook(encoding="utf-8", style_compression=0)
# 创建worksheet对象,最后会对应成xls里面的一个sheet。cell_overwrite_ok=True:覆盖单元格
worksheet = workbook.add_sheet("豆瓣电影top250", cell_overwrite_ok=True)
col = ("电影详情链接", "电影图片链接", "电影题目(中)", "电影题目(外/繁)", "电影评分", "评分人数", "电影简评", "相关信息")
# 填充列名
for i in range(0, len(col)):
worksheet.write(0, i, col[i])
for i in range(0, len(datalist)):
data=datalist[i]
for j in range(0,len(data)):
worksheet.write(i+1, j, data[j])
print("写入了第%d部电影信息" % (i + 1))
workbook.save(savepath)
print("finished:saveData()")
# 其他单独方法
# 得到一个指定url内容的方法
def askURL(url):
html = ""
# 模拟浏览器请求头信息
head = {
# 用户代理,告诉服务器我们是什么类型的机器/浏览器,本质是告诉服务器我们能接收什么水平的文件
# 从浏览器F12里复制时请尽量让该信息在一行里显示再赋值,不然复制过来也是多行而且数据中间有很多空格,有可能出问题
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3870.400 QQBrowser/10.8.4405.400"
}
# 模拟的总请求信息
request = urllib.request.Request(url, headers=head)
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
# 可以输出测试
# print(html)
except urllib.error.URLError as e:
# 如果e有code,打印code
if hasattr(e, "code"):
print(e.code)
# 如果e有reason,打印reason
if hasattr(e, "reason"):
print(e.reason)
return html
if __name__ == '__main__':
main()
print("爬取完毕!")
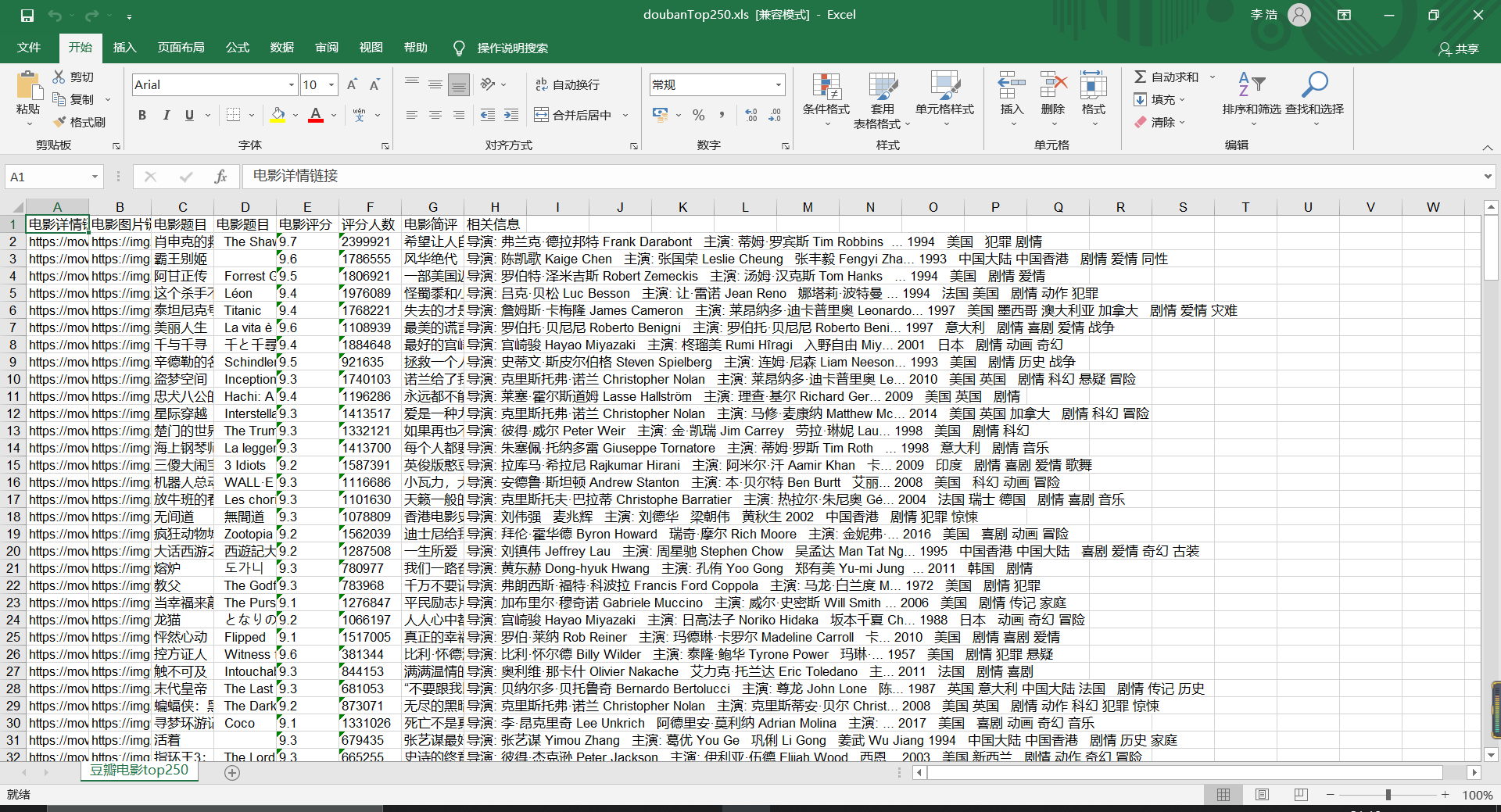
打开xls文件可以看到相关信息已全部录入:
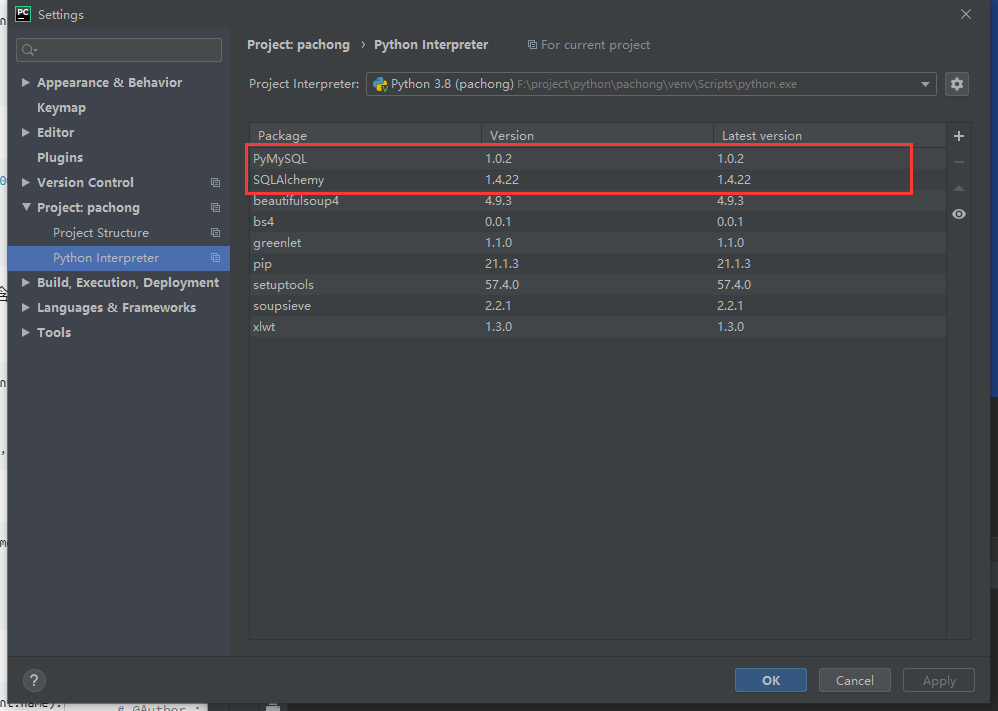
3.4.3完善pachong.py-数据持久化到数据库中
首先安装sqlalchemy,作用和java中的mybatis差不多
pip3 install sqlalchemy
pip3 install pymysql
可选:或者像原来一样从setting里安装也行:
pachong.py:
# -*- coding = utf-8 -*-
# @Time : 2021/7/19 17:18
# @Author : coderhao
# @File : pachong.py
# @Software : PyCharm
# 网页解析,获取数据
from bs4 import BeautifulSoup
# 正则表达式,文字匹配
import re
# 制定url,获取网页数据
import urllib.request, urllib.error
# 进行excel操作
import xlwt
# 进行sqlite数据库操作
import sqlite3
def main():
# 访问url
baseurl = "https://movie.douban.com/top250?start="
# 保存路径
savepath = "doubanTop250.xls"
# 1.爬取网页
datalist = getData(baseurl)
# 3.保存数据(excel/mysql二选一)
# 3.1使用excel保存数据
# saveData1(savepath, datalist)
# 3.2使用mysql保存数据
saveData2(datalist)
# 全局变量
# re.compile()创建正则规则
'''
对照规则:
<div class="item">
<div class="pic">
<em class="">1</em>
<a href="https://movie.douban.com/subject/1292052/">
<img alt="肖申克的救赎" class="" src="https://img2.doubanio.com/view/photo/s_ratio_poster/public/p480747492.jpg" width="100"/>
</a>
</div>
<div class="info">
<div class="hd">
<a class="" href="https://movie.douban.com/subject/1292052/">
<span class="title">肖申克的救赎</span>
<span class="title"> / The Shawshank Redemption</span>
<span class="other"> / 月黑高飞(港) / 刺激1995(台)</span>
</a>
<span class="playable">[可播放]</span>
</div>
<div class="bd">
<p class="">
导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...<br/>
1994 / 美国 / 犯罪 剧情
</p>
<div class="star">
<span class="rating5-t"></span>
<span class="rating_num" property="v:average">9.7</span>
<span content="10.0" property="v:best"></span>
<span>2399691人评价</span>
</div>
<p class="quote">
<span class="inq">希望让人自由。</span>
</p>
</div>
</div>
</div>
'''
findlink = re.compile(r'a href="(.*?)">')
# re.S忽略换行符
# findImgSrc=re.compile(r'<img.*src="(.*?)" width="100"/>',re.S)
findImgSrc = re.compile(r'<img alt=".*" class="" src="(.*?)" width="100"/>', re.S)
findTitle = re.compile(r'<span class="title">(.*?)</span>')
findRating = re.compile(r'<span class="rating_num" property="v:average">(.*?)</span>')
findJudge = re.compile(r'<span>(\d*?)人评价</span>')
findInq = re.compile(r'<span class="inq">(.*?)</span>')
findBd = re.compile(r'<p class="">(.*?)</p>', re.S)
# 1.爬取网页
def getData(baseurl):
print("start:getData()")
datalist = []
# 通过循环得到所有的url
# range函数左闭右开
for i in range(0, 10):
url = baseurl + str(i * 25)
html = askURL(url)
# 2.解析数据
# 第一步网页爬取是个循环过程,所以,解析过程也是跟在爬到的每个网页后面的,更恰当地说这一步应该是在第一步内部
# 解析器选择,并解析
soup = BeautifulSoup(html, "html.parser")
# 遍历符合要求的字符串,形成列表。需要的是<div class="info">的内部内容
for item in soup.find_all("div", class_="item"):
# item存的一个电影的信息
# print(item)
# 用来保存一部电影的所有信息
data = []
item = str(item)
# 影片详情链接
link = re.findall(findlink, item)[0]
# print("link:" + link)
data.append(link)
# 影片图片url
imgSrc = re.findall(findImgSrc, item)[0]
# print("imgSrc:" + imgSrc)
data.append(imgSrc)
# 影片题目
title = re.findall(findTitle, item)
if (len(title) == 2):
# 中文名
ctitle = title[0]
# 外文名
otitle = title[1].replace("/", "") # 去掉/
data.append(ctitle)
data.append(otitle)
else:
data.append(title[0])
data.append(' ') # 留空
# print("ctitle:" + ctitle + "otitle:" + otitle)
# 影片评分
rating = re.findall(findRating, item)[0]
# print("rating:" + rating)
data.append(rating)
# 评分人数
judge = re.findall(findJudge, item)[0]
# print("judge:" + judge)
data.append(judge)
# 影片简述
inq = re.findall(findInq, item)
if (len(inq) != 0):
inq = inq[0].replace("。", "")
data.append(inq)
else:
data.append(" ")
inq = " "
# print("inq:" + inq)
# 影片导演、主演、年份、国家、类型
bd = re.findall(findBd, item)[0]
bd = re.sub('<br(\s+)?/>(\s+)?', " ", bd)
bd = re.sub('/', " ", bd)
data.append(bd.strip()) # bd.strip()去空格
# print("bd:" + bd)
# 使用一个影片测试的时候,可以放开break
# break
# 将html解析后的信息加入到datalist中
datalist.append(data)
print("finished:getData()")
return datalist
# 3.保存数据
# 3.1保存到excel中
def saveData1(savepath, datalist):
print("start:saveData()")
# 创建workbook对象,最后会对应成一个.xls。style_compression=0:样式压缩
workbook = xlwt.Workbook(encoding="utf-8", style_compression=0)
# 创建worksheet对象,最后会对应成xls里面的一个sheet。cell_overwrite_ok=True:覆盖单元格
worksheet = workbook.add_sheet("豆瓣电影top250", cell_overwrite_ok=True)
col = ("电影详情链接", "电影图片链接", "电影题目(中)", "电影题目(外/繁)", "电影评分", "评分人数", "电影简评", "相关信息")
# 填充列名
for i in range(0, len(col)):
worksheet.write(0, i, col[i])
for i in range(0, len(datalist)):
data=datalist[i]
for j in range(0,len(data)):
worksheet.write(i+1, j, data[j])
print("写入了第%d部电影信息" % (i + 1))
workbook.save(savepath)
print("finished:saveData()")
# 3.2保存到mysql中
'''
sql建表语句:
CREATE TABLE `douban_top250` (
`id` int NOT NULL AUTO_INCREMENT COMMENT 'id',
`link` varchar(100) DEFAULT NULL COMMENT '影片详情链接',
`imgSrc` varchar(100) DEFAULT NULL COMMENT '影片图片url',
`ctitle` varchar(100) DEFAULT NULL COMMENT '影片题目(中)',
`otitle` varchar(100) DEFAULT NULL COMMENT '影片题目(外/繁)',
`rating` varchar(100) DEFAULT NULL COMMENT '影片评分',
`judge` bigint DEFAULT NULL COMMENT '评分人数',
`inq` varchar(100) DEFAULT NULL COMMENT '影片简述',
`bd` varchar(200) DEFAULT NULL COMMENT '影片导演、主演、年份、国家、类型',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
'''
# 将保存到excel中的方法设为saveData1,保存到mysql中的方法设为saveData2
def saveData2(datalist):
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine, Column, Integer, String
from sqlalchemy.orm import sessionmaker
HOST = 'localhost'
PORT = 3306
USERNAME = 'root'
PASSWORD = 'password'
DB = 'security_enterprise' #数据库名
# dialect + driver://username:passwor@host:port/database
# +'?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&nullCatalogMeansCurrent=true'
DB_URI = f'mysql+pymysql://{USERNAME}:{PASSWORD}@{HOST}:{PORT}/{DB}'
# 创建基类
BASE = declarative_base()
# 定义Movie对象
# 定义ORM映射对象时,要与建表语句保持一致
class Movie(BASE):
# 表的名字:douban_top250
__tablename__ = 'douban_top250'
# id
id = Column(Integer, primary_key=True, autoincrement=True)
# 学号
link = Column(String(100))
# imgSrc
imgSrc = Column(String(100))
# ctitle
ctitle = Column(String(100))
# otitle
otitle = Column(String(100))
# rating
rating = Column(String(100))
# judge
judge = Column(Integer)
# inq
inq = Column(String(100))
# bd
bd = Column(String(200))
# 创建表的参数
__table_args__ = {
"mysql_charset": "utf8"
}
try:
# 连接MySQL数据库
MySQLEngine = create_engine(DB_URI)
# 创建MySQL类型
MySQLSession = sessionmaker(bind=MySQLEngine)
# 创建session对象
session = MySQLSession()
# 使用ORM插入数据
for i in range(0,len(datalist)):
data=datalist[i]
# 创建movie对象
movie=Movie(link=data[0],imgSrc=data[1],ctitle=data[2],otitle=data[3],rating=data[4],judge=data[5],inq=data[6],bd=data[7])
# 将创建的对象添加进session中
session.add(movie)
# 使用原生SQL插入数据
# session.execute(
# "INSERT INTO STUDENT VALUES('2016081115','吴芳'),('2016081116','胡月')")
# 提交到数据库
# 如果提交失败,会自动回滚
session.commit()
# 关闭session
session.close()
print('插入MySQL数据库成功')
except Exception as e:
print("插入MySQL数据库失败", e)
# 其他单独方法
# 得到一个指定url内容的方法
def askURL(url):
html = ""
# 模拟浏览器请求头信息
head = {
# 用户代理,告诉服务器我们是什么类型的机器/浏览器,本质是告诉服务器我们能接收什么水平的文件
# 从浏览器F12里复制时请尽量让该信息在一行里显示再赋值,不然复制过来也是多行而且数据中间有很多空格,有可能出问题
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3870.400 QQBrowser/10.8.4405.400"
}
# 模拟的总请求信息
request = urllib.request.Request(url, headers=head)
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
# 可以输出测试
# print(html)
except urllib.error.URLError as e:
# 如果e有code,打印code
if hasattr(e, "code"):
print(e.code)
# 如果e有reason,打印reason
if hasattr(e, "reason"):
print(e.reason)
return html
if __name__ == '__main__':
main()
print("爬取完毕!")
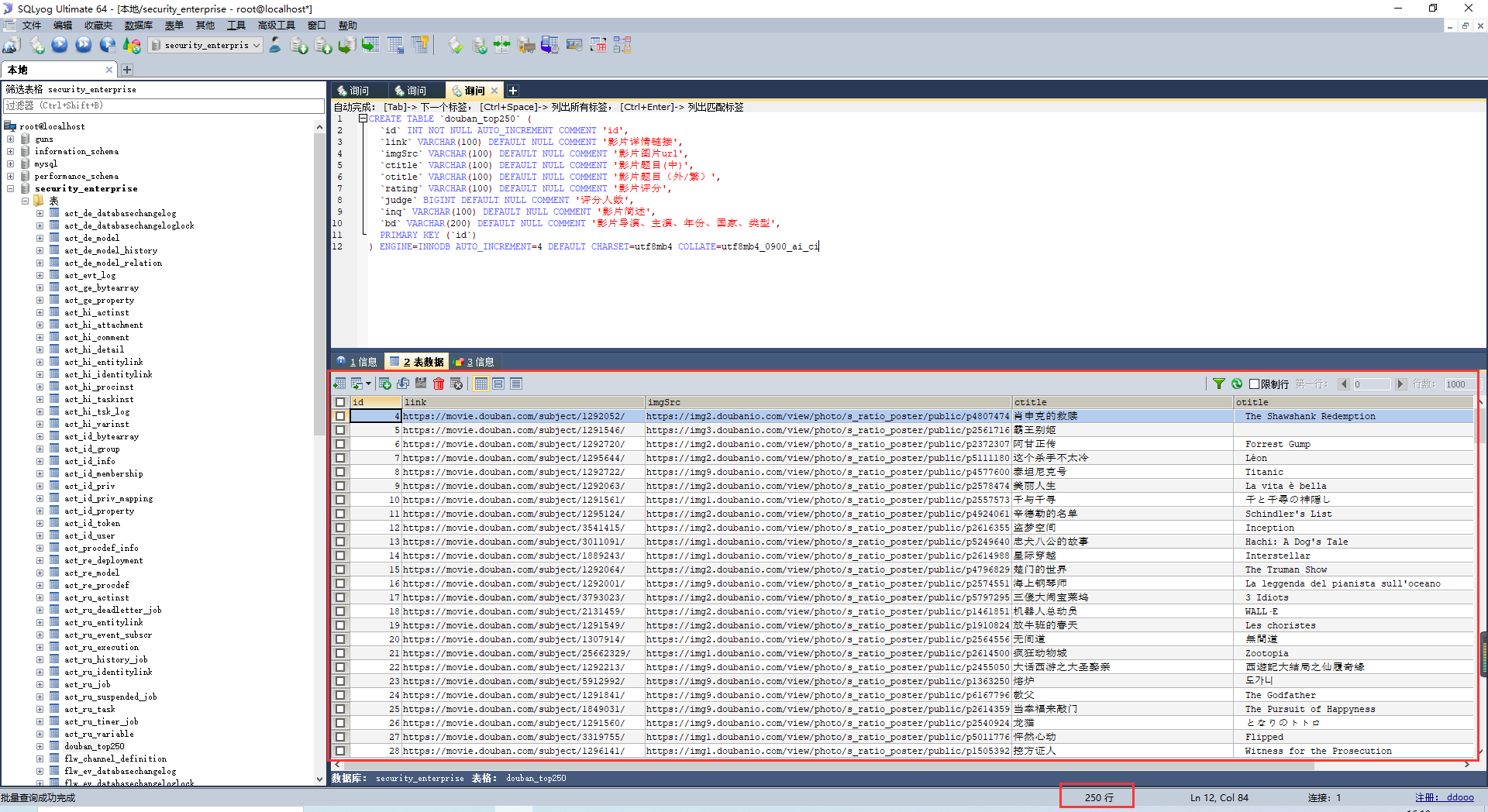
在数据库中可以看到已经存入:
原文链接:https://blog.csdn.net/anotherQu/article/details/118899366
所属网站分类: 技术文章 > 博客
作者:每个人身上都有毛毛
链接:http://www.pythonpdf.com/blog/article/546/85a83b9cca2d1432620f/
来源:编程知识网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)