
绝密!Python告诉你升级神器背后的原理!这篇文章差点没过审
发布于2021-07-25 07:19 阅读(788) 评论(0) 点赞(23) 收藏(4)
声明
本文内容只作学习交流之用,请勿将其用于商业和非学习用途和违反CSDN 用户准则、违法违规的行为。
今天我百无聊赖刷着 CSDN 的时候,看到了官方博客的帮助文档:
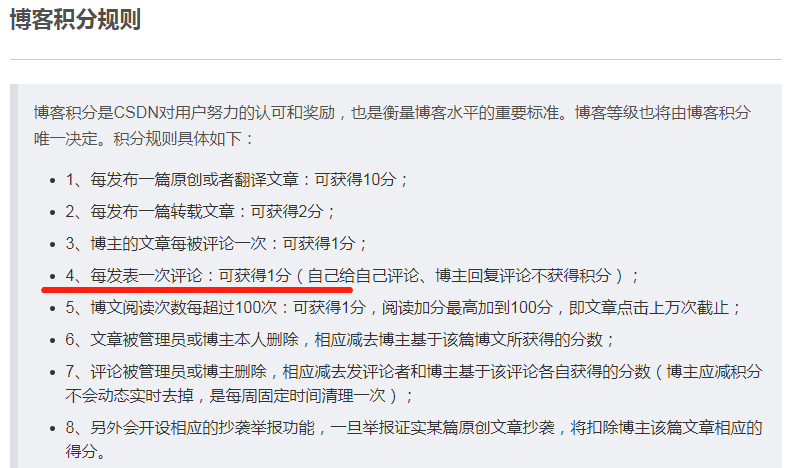
看到这个我顿时精神就上来了。CSDN等级的提升需要积分,要是写一写评论就能够得到分,那不爽歪歪?(剧情需要,请勿模仿!!!)
当然,刷分的事情我是不会去做的。现在来以发送评论为例介绍 requests 库(这才是重点!)
随便找一篇别人的博客:
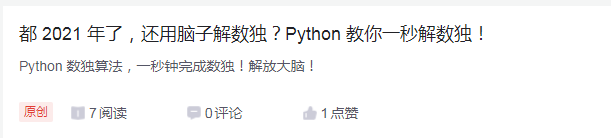
这个标题让人看上去就很不爽,真欠打。决定了,就拿你当我的小白鼠!
马上,开整!
requests 库
这个机器需要用到的库很简单:requests。首先cmd打开命令行安装库:
pip install requests
然后在 Python 中导入:
import requests
网页
随便打开一篇博客(就以刚刚那篇欠揍的博客为例),首先看搜索栏的网址,看最后这几个数字,这是该篇博文的 id,这个要记住,这个在待会会用到:

然后我们在博客页面单击右键,选择“检查元素”,不同的浏览器可能会不一样,有可能只是“检查”或是其他,自己试一下。然后会弹出一个检查窗口,里面有一堆乱七八糟的东西:
接下来点击右上角的“Network”(网络)。点击左上角的圆点使他变成红色,开始录制动作:
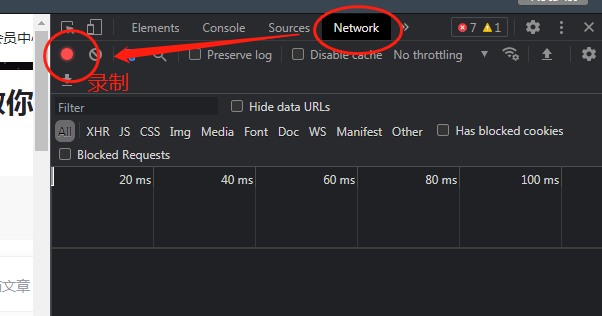
接下来我们就滑到评论区,随便写下一条评论并发送(不要做多余的动作),浏览器会记录下我们所做的网络活动。我们可以看到我们所做的网络活动,在这些活动中寻找最有可能的一条(可能会有些麻烦,慢慢找,不着急),点开来查看我们的活动。怎么找到自己需要的是哪一条呢,这里有一个方便的方法,一个个点开来,在Headers(请求头)栏滑到最下面,看到它有出现我们需要的信息,那么大概率就是这个了:
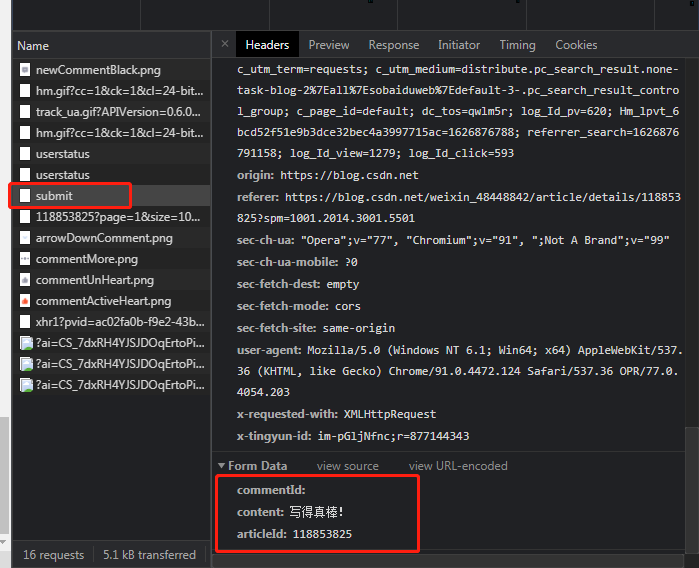
在这里我的是 submit。
接下来我们回到 Headers 栏的顶端,这里有网页请求的一些基本信息:
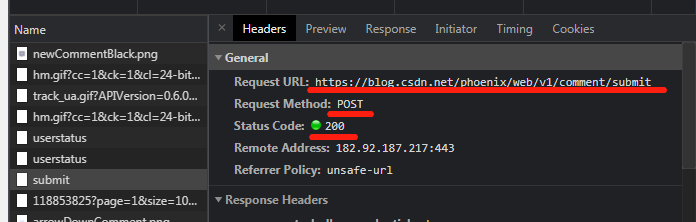
URL是进行网页请求的地址,注意这个与你在上面搜索栏看到的是不一样的。Method 后的POST是请求方式。Status Code是状态码,200表示请求成功。POST方式就要使用类的 post 方法:
requests.post(url=<url地址>, headers=<请求头>, data=<信息>)
首先是 url,我们需要一个变量(字符串类型)来存储这个url地址:
url = 'https://blog.csdn.net/phoenix/web/v1/comment/submit'
接下来是请求头,请求头就是Requests Headers 这一部分,用一个字典存储:
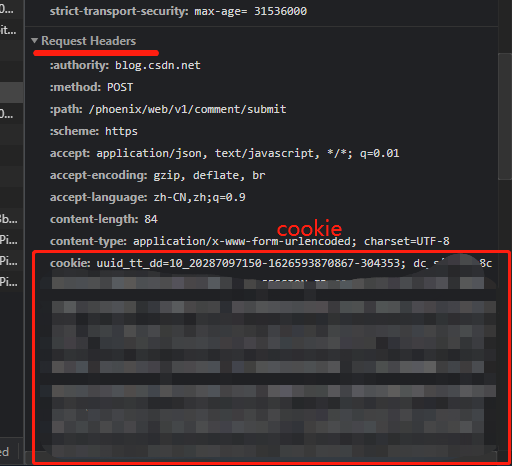
比较重要的是 cookie。这里我把 cookie 部分和 user-agent 部分复制下来放到请求头字典中去:
headers = {
'cookie': 'uuid_tt_dd=10_20287097150-1626593870867-304353...'
'user_agent': 'Mozilla/5.0...'
}
这个 cookie 是什么呢,其实它的作用是传输了用户的信息、身份,就好比你登录了 CSDN 之后,你再进入这个网页时就不需要再登陆了,因为浏览器已经保存了你的身份信息并发给了网页。由于评论文章需要登录后才可进行,因此你必须在已登录状态下获取 cookie,并且在发送请求时必须带上这个 cookie,否则无法进行评论操作。
最后是 data,再滑到最底部,看到一些信息,这就是 data,同样以字典形式保存:
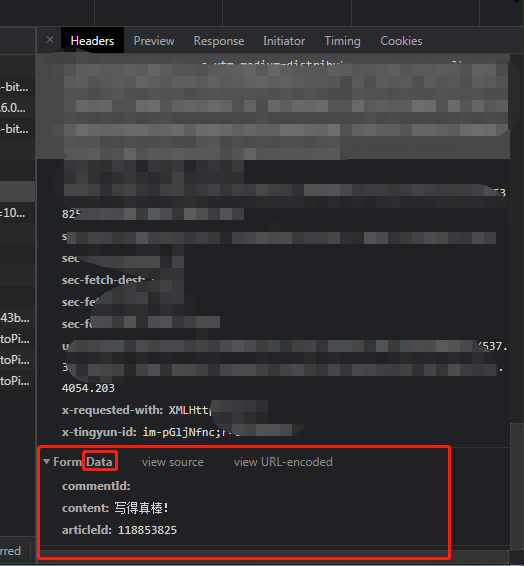
data = {
'commentId': '',
'content': '写得真棒!',
'articleId': '118853825',
}
于是我们就可以用 post 方法来发送请求获得响应结果了:
respond = requests.post(url=url, headers=headers, data=data) # 发送请求并将响应结果放入respond变量
然后我们还要看看请求结果
print(data['areticleId']) # 打印文章id
print(respond.status_code) # 打印状态码
print(respond.text) # 打印返回文本
print(respond.json()['message']) # 打印返回文本经json解码后的message部分
输出:
118853825
200
{"code":200,"message":"success","data":17638523}
success
再看回那个欠揍的博客:

十分成功!
这样,我们就完成了对这篇文章的评论。但是我们要达到效果,必须不断访问不同的文章,这个时候我们的文章 id 就派上用场啦。我们可以发现,data 中的 articleId,其实就是文章的 id,这样我们只需生成不同的文章 id,然后放到 articleId 中,再进行评论就可以了(我只是在教你们访问不同博客的方法,并不倡导你们刷分):
import time
for i in range(100000000, 100000050):
data.update({'articleId': str(i)}) # 刷新
respond = requests.post(url=url, headers=headers, data=data)
print(data['articleId']) # 打印文章id
print(respond.status_code) # 打印状态码
print(respond.json()['message']) # 打印返回文本经json解码后的message部分
time.sleep(2)
由于频繁评论会导致被提示“您评论次数太多了,请休息一下!”,因此我还导入了 time 库,在每一次评论后等待两秒再评论。
来看看最后的效果:
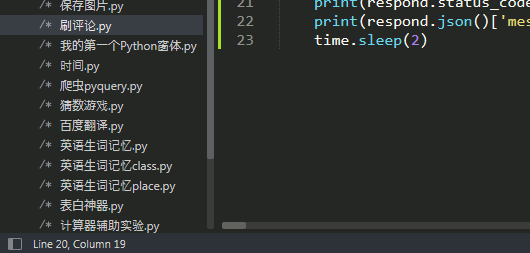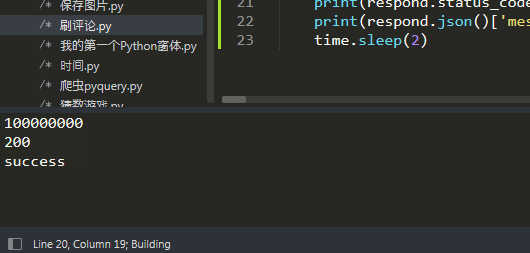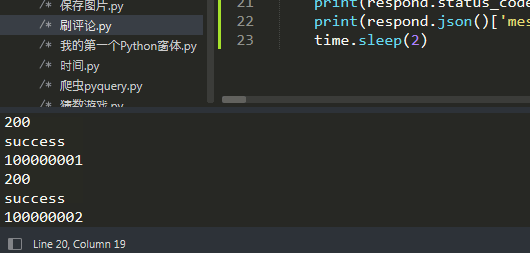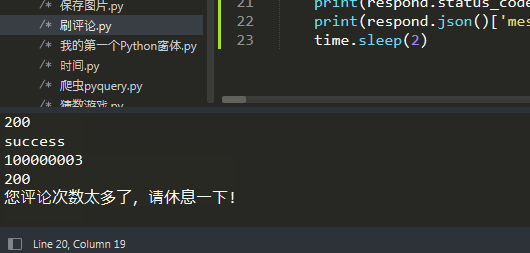
成功!(学到了 requests 的使用方法就好,不要拿它来干违法违规的事情!)
优化后的代码
import requests
import time
url = 'https://blog.csdn.net/phoenix/web/v1/comment/submit'
headers = {
'cookie': 'uuid_tt_dd=10_20287097150-1626593870867-304353...'
'user_agent': 'Mozilla/5.0...'
}
data = {
'commentId': '',
'content': '写得真棒!',
'articleId': '118853825',
}
for i in range(100000000, 100000050):
data.update({'articleId': str(i)})
respond = requests.post(url=url, headers=headers, data=data)
print(data['articleId']) # 打印文章id
print(respond.status_code) # 打印状态码
print(respond.json()['message']) # 打印返回文本经json解码后的message部分
time.sleep(2)
尾声
本篇文章主要介绍了 requests 库的简单的使用方法,刷分的行为不建议模仿,分数还是要靠自己写文章等的正当途径慢慢挣的好。最后还要感谢您完整地看完这篇文章。
2021/7/22
声明
本文内容只作学习交流之用,请勿将其用于商业和非学习用途和违反CSDN 用户准则、违法违规的行为。
原文链接:https://blog.csdn.net/weixin_52132159/article/details/118990062
所属网站分类: 技术文章 > 博客
作者:你做的菜有点咸
链接:http://www.pythonpdf.com/blog/article/550/04bfb2a46b1c64a12043/
来源:编程知识网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)