
用python爬取腾讯招聘网岗位信息保存到表格,并做成简单可视化。(附源码)
发布于2021-07-18 20:28 阅读(1027) 评论(0) 点赞(23) 收藏(3)
用python爬取腾讯招聘网岗位信息保存到表格,并做成可视化。
代码运行展示
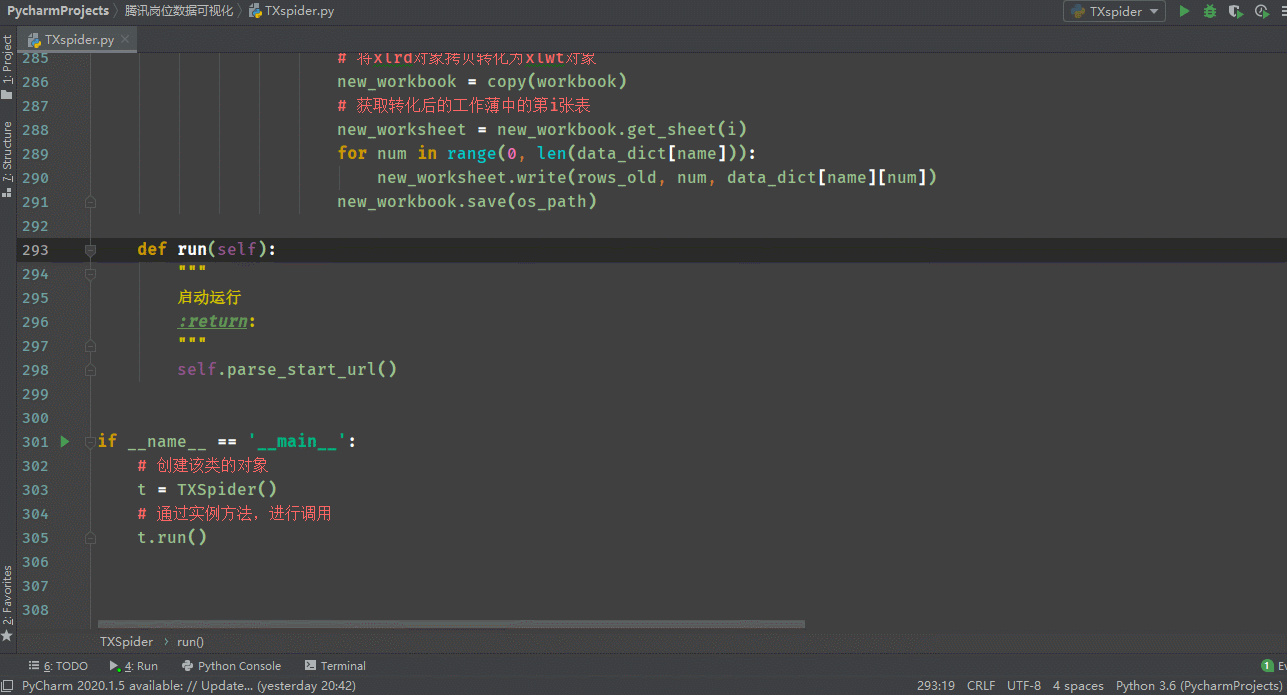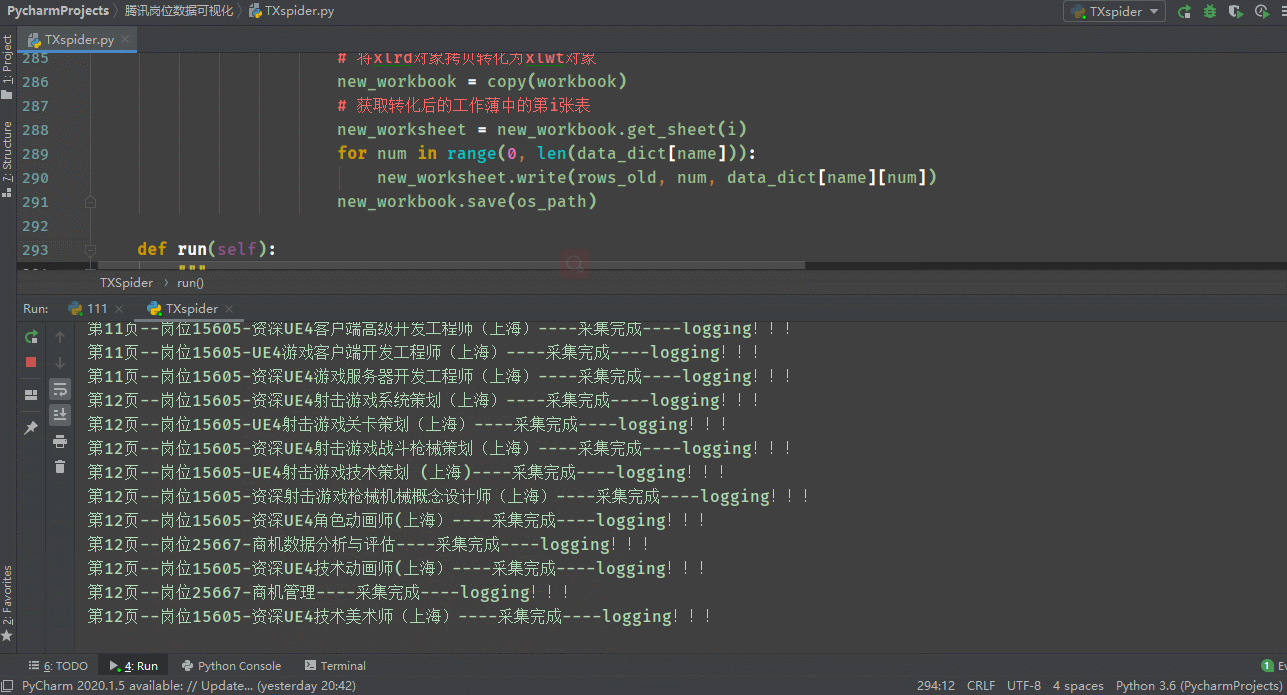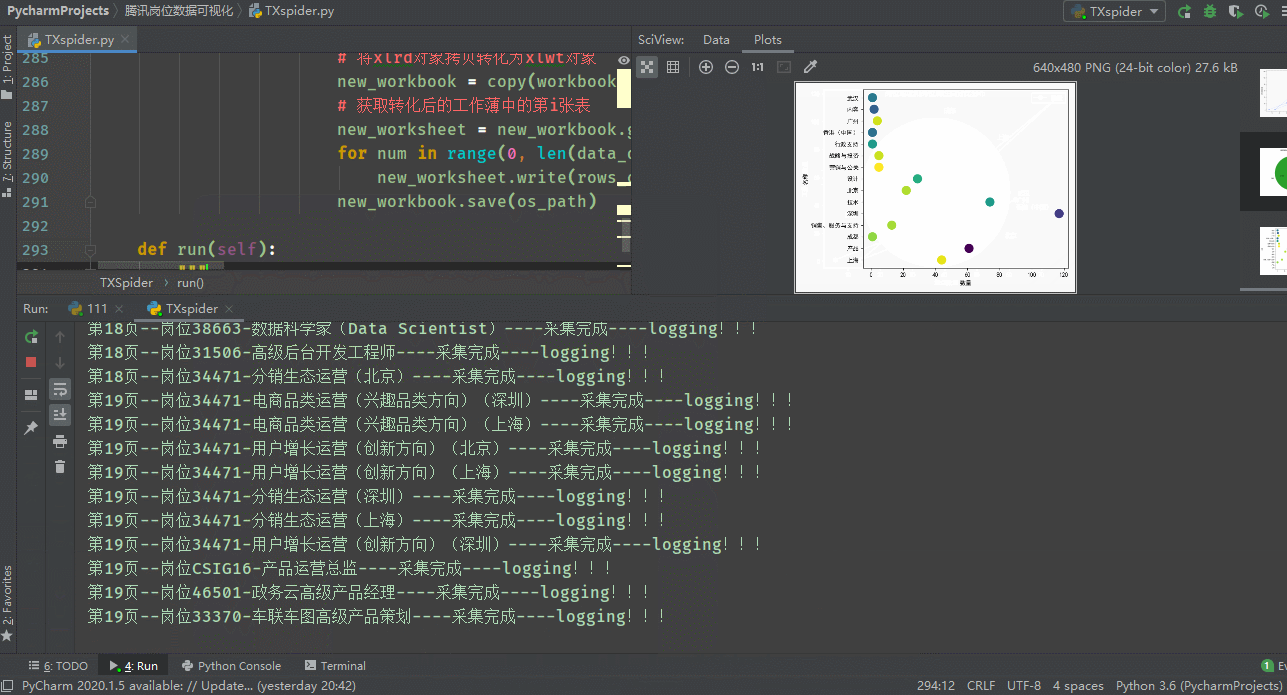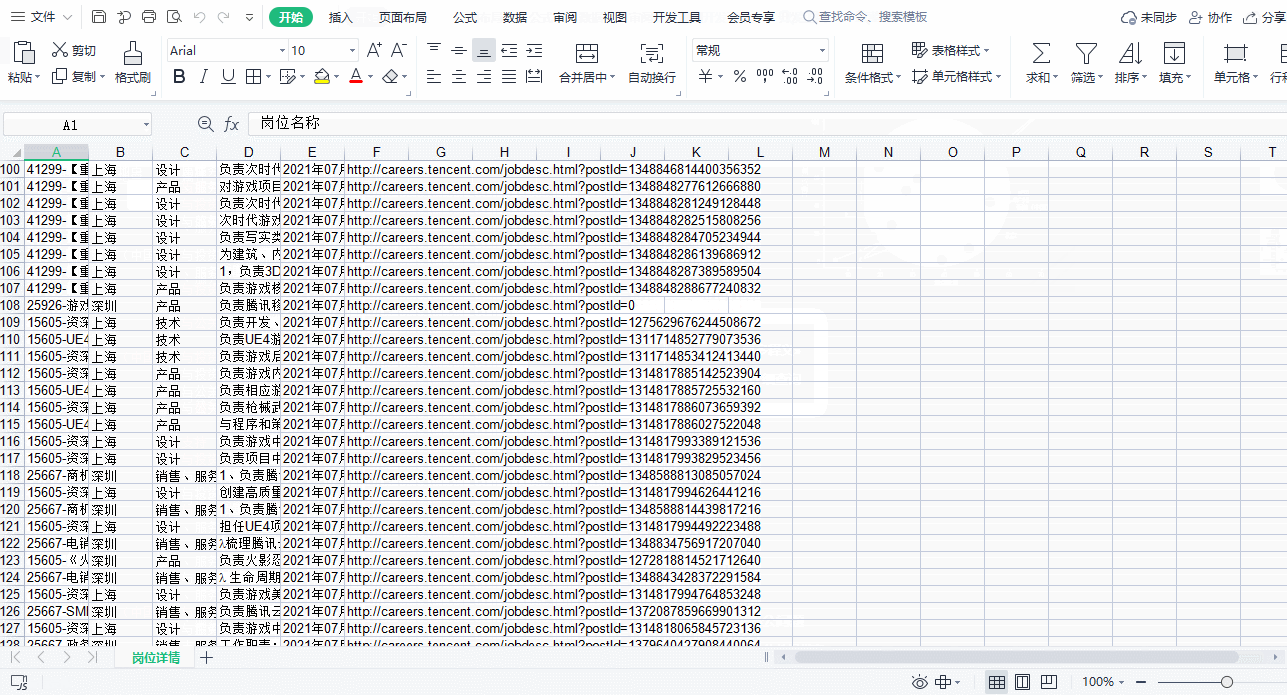

开发环境
Windows 10
python3.6
开发工具
pycharm
库
numpy、matplotlib、time、xlutils.copy、os、xlwt, xlrd, random
开发思路
1.打开腾讯招聘的网址右击检查进行抓包,进入网址的时候发现有异步渲染,我们要的数据为异步加载
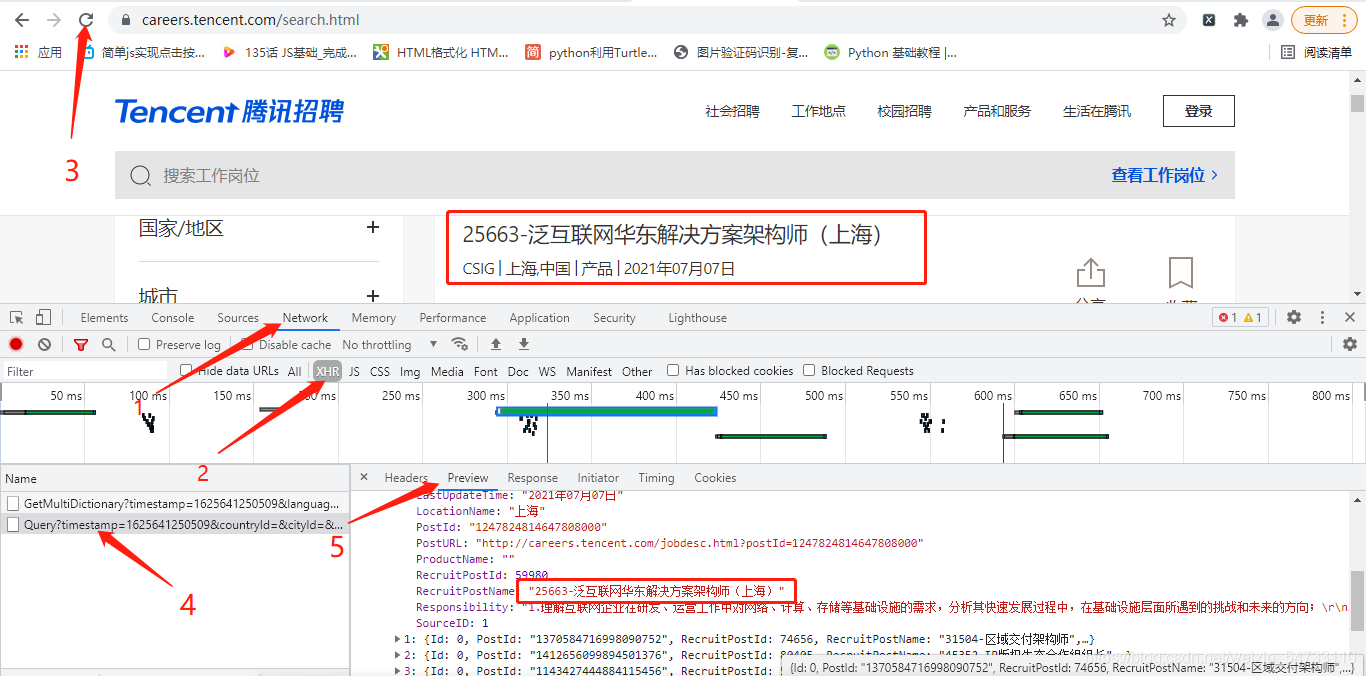
2.构造起始地址:
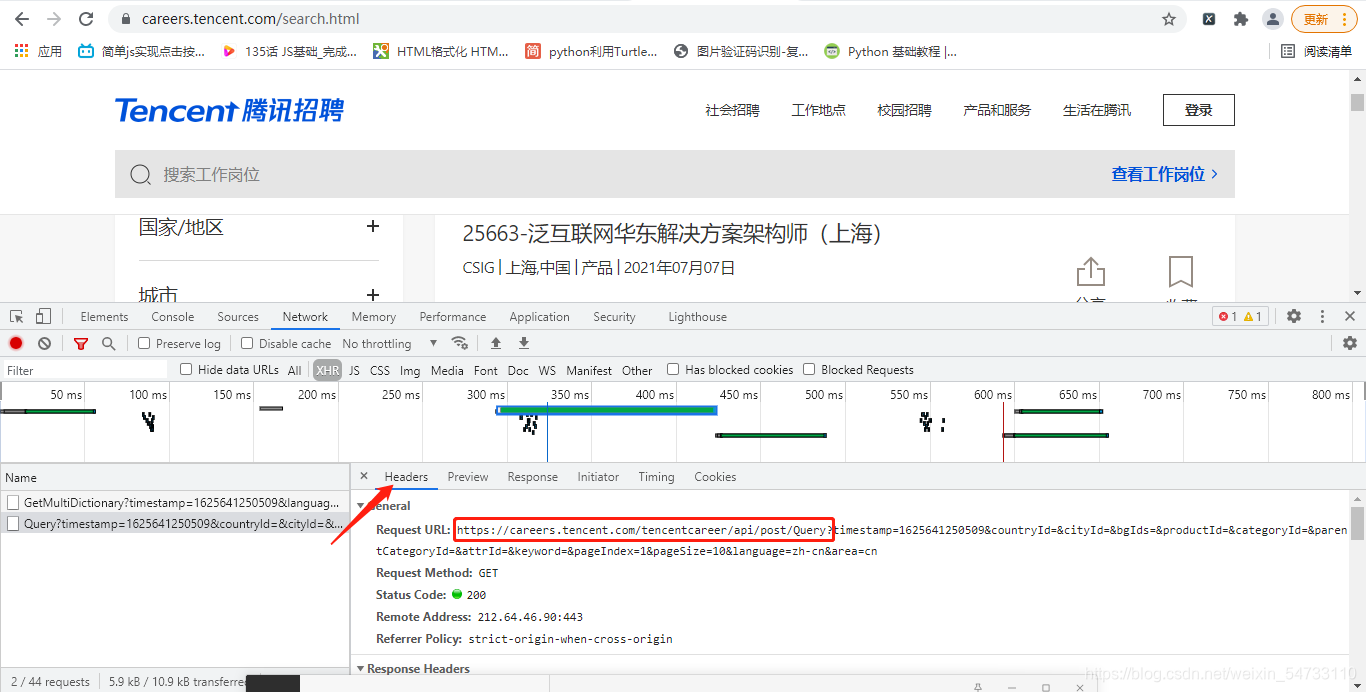
start_url = ‘https://careers.tencent.com/tencentcareer/api/post/Query’
参数在headers的最下面
timestamp: 1625641250509
countryId:
cityId:
bgIds:
productId:
categoryId:
parentCategoryId:
attrId:
keyword:
pageIndex: 1
pageSize: 10
language: zh-cn
area: cn
3.发送请求,获取响应
self.start_url = 'https://careers.tencent.com/tencentcareer/api/post/Query'
# 构造请求参数
params = {
# 捕捉当前时间戳
'timestamp': str(int(time.time() * 1000)),
'countryId': '',
'cityId': '',
'bgIds': '',
'productId': '',
'categoryId': '',
'parentCategoryId': '',
'attrId': '',
'keyword': '',
'pageIndex': str(self.start_page),
'pageSize': '10',
'language': 'zh-cn',
'area': 'cn'
}
headers = {
'user-agent': random.choice(USER_AGENT_LIST)
}
response = session.get(url=self.start_url, headers=headers, params=params).json()
4.提取数据,获取岗位信息大列表,提取相应的数据
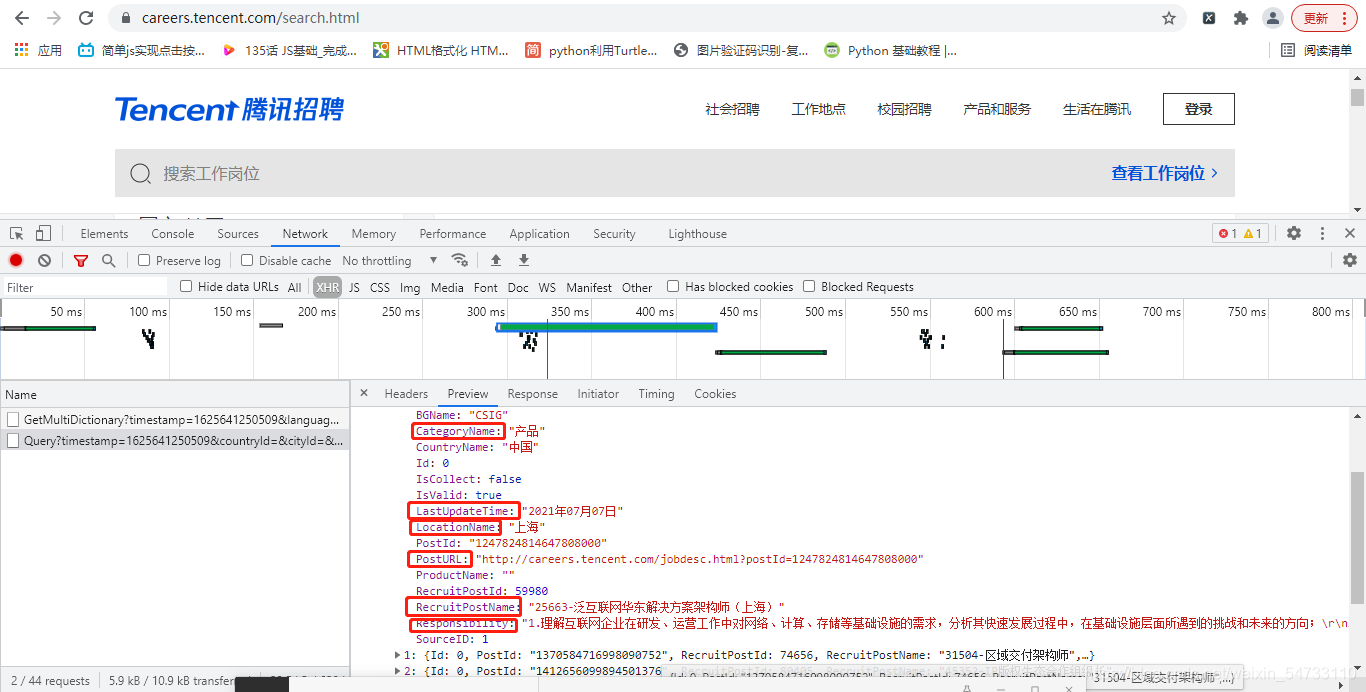
# 获取岗位信息大列表
json_data = response['Data']['Posts']
# 判断结果是否有数据
if json_data is None:
# 没有数据,设置循环条件为False
self.is_running = False
# 反之,开始提取数据
else:
# 循环遍历,取出列表中的每一个岗位字典
# 通过key取value值的方法进行采集数据
for data in json_data:
# 工作地点
LocationName = data['LocationName']
# 往地址大列表中添加数据
self.addr_list.append(LocationName)
# 工作属性
CategoryName = data['CategoryName']
# 往工作属性大列表中添加数据
self.category_list.append(CategoryName)
# 岗位名称
RecruitPostName = data['RecruitPostName']
# 岗位职责
Responsibility = data['Responsibility']
# 发布时间
LastUpdateTime = data['LastUpdateTime']
# 岗位地址
PostURL = data['PostURL']
5.数据生成折线图、饼图、散点图、柱状图
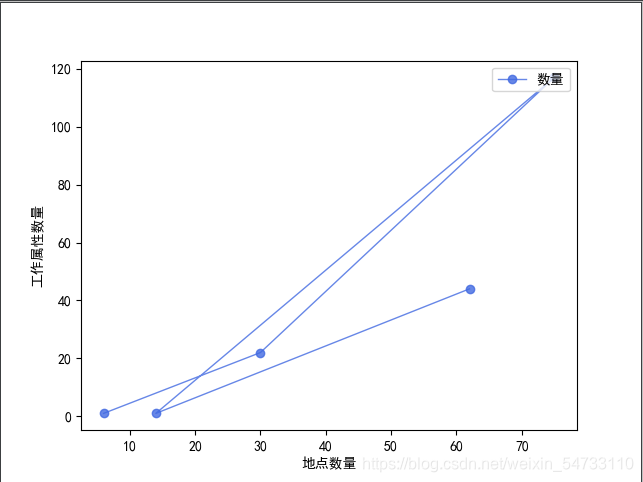
# 第一张图:根据岗位地址和岗位属性二者数量生成折线图
# 146,147两行代码解决图中中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 由于二者数据数量不统一,在此进行切片操作
x_axis_data = [i for i in addr_dict.values()][:5]
y_axis_data = [i for i in cate_dict.values()][:5]
# print(x_axis_data, y_axis_data)
# plot中参数的含义分别是横轴值,纵轴值,线的形状,颜色,透明度,线的宽度和标签
plt.plot(y_axis_data, x_axis_data, 'ro-', color='#4169E1', alpha=0.8, linewidth=1, label='数量')
# 显示标签,如果不加这句,即使在plot中加了label='一些数字'的参数,最终还是不会显示标签
plt.legend(loc="upper right")
plt.xlabel('地点数量')
plt.ylabel('工作属性数量')
plt.savefig('根据岗位地址和岗位属性二者数量生成折线图.png')
plt.show()
# 第二张图:根据岗位地址数量生成饼图
"""工作地址饼图"""
addr_dict_key = [k for k in addr_dict.keys()]
addr_dict_value = [v for v in addr_dict.values()]
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
plt.pie(addr_dict_value, labels=addr_dict_key, autopct='%1.1f%%')
plt.title(f'岗位地址和岗位属性百分比分布')
plt.savefig(f'岗位地址和岗位属性百分比分布-饼图')
plt.show()
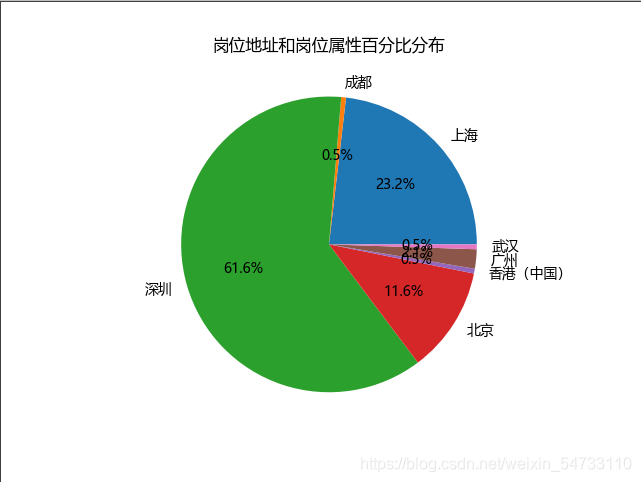
# 第三张图:根据岗位地址和岗位属性二者数量生成散点图
# 这两行代码解决 plt 中文显示的问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 输入岗位地址和岗位属性数据
production = [i for i in data.keys()]
tem = [i for i in data.values()]
colors = np.random.rand(len(tem)) # 颜色数组
plt.scatter(tem, production, s=200, c=colors) # 画散点图,大小为 200
plt.xlabel('数量') # 横坐标轴标题
plt.ylabel('名称') # 纵坐标轴标题
plt.savefig(f'岗位地址和岗位属性散点图')
plt.show()
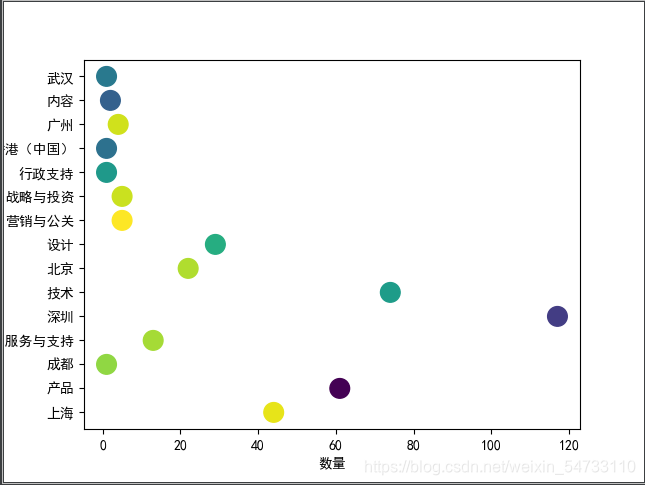
# 第四张图:根据岗位地址和岗位属性二者数量生成柱状图
import matplotlib;matplotlib.use('TkAgg')
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
zhfont1 = matplotlib.font_manager.FontProperties(fname='C:\Windows\Fonts\simsun.ttc')
name_list = [name for name in data.keys()]
num_list = [value for value in data.values()]
width = 0.5 # 柱子的宽度
index = np.arange(len(name_list))
plt.bar(index, num_list, width, color='steelblue', tick_label=name_list, label='岗位数量')
plt.legend(['分解能耗', '真实能耗'], prop=zhfont1, labelspacing=1)
for a, b in zip(index, num_list): # 柱子上的数字显示
plt.text(a, b, '%.2f' % b, ha='center', va='bottom', fontsize=7)
plt.xticks(rotation=270)
plt.title('岗位数量和岗位属性数量柱状图')
plt.ylabel('次')
plt.legend()
plt.savefig(f'岗位数量和岗位属性数量柱状图-柱状图', bbox_inches='tight')
plt.show()
源码展示:
"""ua大列表"""
USER_AGENT_LIST = [
'Mozilla/5.0 (Windows NT 6.2; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.90 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3451.0 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:57.0) Gecko/20100101 Firefox/57.0',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1500.71 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.2999.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.70 Safari/537.36',
'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10.4; en-US; rv:1.9.2.2) Gecko/20100316 Firefox/3.6.2',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.155 Safari/537.36 OPR/31.0.1889.174',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.1.4322; MS-RTC LM 8; InfoPath.2; Tablet PC 2.0)',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36 OPR/55.0.2994.61',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.814.0 Safari/535.1',
'Mozilla/5.0 (Macintosh; U; PPC Mac OS X; ja-jp) AppleWebKit/418.9.1 (KHTML, like Gecko) Safari/419.3',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.2357.134 Safari/537.36',
'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; Trident/6.0; Touch; MASMJS)',
'Mozilla/5.0 (X11; Linux i686) AppleWebKit/535.21 (KHTML, like Gecko) Chrome/19.0.1041.0 Safari/535.21',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.2; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.90 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3451.0 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:57.0) Gecko/20100101 Firefox/57.0',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1500.71 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.2999.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.70 Safari/537.36',
'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10.4; en-US; rv:1.9.2.2) Gecko/20100316 Firefox/3.6.2',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.155 Safari/537.36 OPR/31.0.1889.174',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.1.4322; MS-RTC LM 8; InfoPath.2; Tablet PC 2.0)',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36 OPR/55.0.2994.61',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.814.0 Safari/535.1',
'Mozilla/5.0 (Macintosh; U; PPC Mac OS X; ja-jp) AppleWebKit/418.9.1 (KHTML, like Gecko) Safari/419.3',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.2357.134 Safari/537.36',
'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; Trident/6.0; Touch; MASMJS)',
'Mozilla/5.0 (X11; Linux i686) AppleWebKit/535.21 (KHTML, like Gecko) Chrome/19.0.1041.0 Safari/535.21',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4093.3 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko; compatible; Swurl) Chrome/77.0.3865.120 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4086.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:75.0) Gecko/20100101 Firefox/75.0',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) coc_coc_browser/91.0.146 Chrome/85.0.4183.146 Safari/537.36',
'Mozilla/5.0 (Windows; U; Windows NT 5.2; en-US) AppleWebKit/537.36 (KHTML, like Gecko) Safari/537.36 VivoBrowser/8.4.72.0 Chrome/62.0.3202.84',
'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.101 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36 Edg/87.0.664.60',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.16; rv:83.0) Gecko/20100101 Firefox/83.0',
'Mozilla/5.0 (X11; CrOS x86_64 13505.63.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:68.0) Gecko/20100101 Firefox/68.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.101 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36 OPR/72.0.3815.400',
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.101 Safari/537.36',
]
from requests_html import HTMLSession
import os, xlwt, xlrd, random
from xlutils.copy import copy
import numpy as np
from matplotlib import pyplot as plt
from matplotlib.font_manager import FontProperties # 字体库
import time
session = HTMLSession()
class TXSpider(object):
def __init__(self):
# 起始的请求地址
self.start_url = 'https://careers.tencent.com/tencentcareer/api/post/Query'
# 起始的翻页页码
self.start_page = 1
# 翻页条件
self.is_running = True
# 准备工作地点大列表
self.addr_list = []
# 准备岗位种类大列表
self.category_list = []
def parse_start_url(self):
"""
解析起始的url地址
:return:
"""
# 条件循环模拟翻页
while self.is_running:
# 构造请求参数
params = {
# 捕捉当前时间戳
'timestamp': str(int(time.time() * 1000)),
'countryId': '',
'cityId': '',
'bgIds': '',
'productId': '',
'categoryId': '',
'parentCategoryId': '',
'attrId': '',
'keyword': '',
'pageIndex': str(self.start_page),
'pageSize': '10',
'language': 'zh-cn',
'area': 'cn'
}
headers = {
'user-agent': random.choice(USER_AGENT_LIST)
}
response = session.get(url=self.start_url, headers=headers, params=params).json()
"""调用解析响应方法"""
self.parse_response_json(response)
"""翻页递增"""
self.start_page += 1
"""翻页终止条件"""
if self.start_page == 20:
self.is_running = False
"""翻页完成,开始生成分析图"""
self.crate_img_four_func()
def crate_img_four_func(self):
"""
生成四张图方法
:return:
"""
# 统计数量
data = {} # 大字典
addr_dict = {} # 工作地址字典
cate_dict = {} # 工作属性字典
for k_addr, v_cate in zip(self.addr_list, self.category_list):
if k_addr in data:
# 大字典统计工作地址数据
data[k_addr] = data[k_addr] + 1
# 地址字典统计数据
addr_dict[k_addr] = addr_dict[k_addr] + 1
else:
data[k_addr] = 1
addr_dict[k_addr] = 1
if v_cate in data:
# 大字典统计工作属性数据
data[v_cate] = data[v_cate] + 1
# 工作属性字典统计数据
cate_dict[v_cate] = data[v_cate] + 1
else:
data[v_cate] = 1
cate_dict[v_cate] = 1
# 第一张图:根据岗位地址和岗位属性二者数量生成折线图
# 146,147两行代码解决图中中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 由于二者数据数量不统一,在此进行切片操作
x_axis_data = [i for i in addr_dict.values()][:5]
y_axis_data = [i for i in cate_dict.values()][:5]
# print(x_axis_data, y_axis_data)
# plot中参数的含义分别是横轴值,纵轴值,线的形状,颜色,透明度,线的宽度和标签
plt.plot(y_axis_data, x_axis_data, 'ro-', color='#4169E1', alpha=0.8, linewidth=1, label='数量')
# 显示标签,如果不加这句,即使在plot中加了label='一些数字'的参数,最终还是不会显示标签
plt.legend(loc="upper right")
plt.xlabel('地点数量')
plt.ylabel('工作属性数量')
plt.savefig('根据岗位地址和岗位属性二者数量生成折线图.png')
plt.show()
# 第二张图:根据岗位地址数量生成饼图
"""工作地址饼图"""
addr_dict_key = [k for k in addr_dict.keys()]
addr_dict_value = [v for v in addr_dict.values()]
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
plt.pie(addr_dict_value, labels=addr_dict_key, autopct='%1.1f%%')
plt.title(f'岗位地址和岗位属性百分比分布')
plt.savefig(f'岗位地址和岗位属性百分比分布-饼图')
plt.show()
# 第三张图:根据岗位地址和岗位属性二者数量生成散点图
# 这两行代码解决 plt 中文显示的问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 输入岗位地址和岗位属性数据
production = [i for i in data.keys()]
tem = [i for i in data.values()]
colors = np.random.rand(len(tem)) # 颜色数组
plt.scatter(tem, production, s=200, c=colors) # 画散点图,大小为 200
plt.xlabel('数量') # 横坐标轴标题
plt.ylabel('名称') # 纵坐标轴标题
plt.savefig(f'岗位地址和岗位属性散点图')
plt.show()
# 第四张图:根据岗位地址和岗位属性二者数量生成柱状图
import matplotlib;matplotlib.use('TkAgg')
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
zhfont1 = matplotlib.font_manager.FontProperties(fname='C:\Windows\Fonts\simsun.ttc')
name_list = [name for name in data.keys()]
num_list = [value for value in data.values()]
width = 0.5 # 柱子的宽度
index = np.arange(len(name_list))
plt.bar(index, num_list, width, color='steelblue', tick_label=name_list, label='岗位数量')
plt.legend(['分解能耗', '真实能耗'], prop=zhfont1, labelspacing=1)
for a, b in zip(index, num_list): # 柱子上的数字显示
plt.text(a, b, '%.2f' % b, ha='center', va='bottom', fontsize=7)
plt.xticks(rotation=270)
plt.title('岗位数量和岗位属性数量柱状图')
plt.ylabel('次')
plt.legend()
plt.savefig(f'岗位数量和岗位属性数量柱状图-柱状图', bbox_inches='tight')
plt.show()
def parse_response_json(self, response):
"""
解析响应
:param response:
:return:
"""
# 获取岗位信息大列表
json_data = response['Data']['Posts']
# 判断结果是否有数据
if json_data is None:
# 没有数据,设置循环条件为False
self.is_running = False
# 反之,开始提取数据
else:
# 循环遍历,取出列表中的每一个岗位字典
# 通过key取value值的方法进行采集数据
for data in json_data:
# 工作地点
LocationName = data['LocationName']
# 往地址大列表中添加数据
self.addr_list.append(LocationName)
# 工作属性
CategoryName = data['CategoryName']
# 往工作属性大列表中添加数据
self.category_list.append(CategoryName)
# 岗位名称
RecruitPostName = data['RecruitPostName']
# 岗位职责
Responsibility = data['Responsibility']
# 发布时间
LastUpdateTime = data['LastUpdateTime']
# 岗位地址
PostURL = data['PostURL']
# 构造保存excel所需要的格式字典
data_dict = {
# 该字典的key值与创建工作簿的sheet表的名称所关联
'岗位详情': [RecruitPostName, LocationName, CategoryName, Responsibility, LastUpdateTime, PostURL]
}
"""调用保存excel表格方法,数据字典作为参数"""
self.save_excel(data_dict)
# 提示输出
print(f"第{self.start_page}页--岗位{RecruitPostName}----采集完成----logging!!!")
def save_excel(self, data_dict):
"""
保存excel
:param data_dict: 数据字典
:return:
"""
# 判断保存到当我文件目录的路径是否存在
os_path_1 = os.getcwd() + '/数据/'
if not os.path.exists(os_path_1):
# 不存在,即创建这个目录,即创建”数据“这个文件夹
os.mkdir(os_path_1)
# 判断将数据保存到表格的这个表格是否存在,不存在,创建表格,写入表头
os_path = os_path_1 + '腾讯招聘数据.xls'
if not os.path.exists(os_path):
# 创建新的workbook(其实就是创建新的excel)
workbook = xlwt.Workbook(encoding='utf-8')
# 创建新的sheet表
worksheet1 = workbook.add_sheet("岗位详情", cell_overwrite_ok=True)
excel_data_1 = ('岗位名称', '工作地点', '工作属性', '岗位职责', '发布时间', '岗位地址')
for i in range(0, len(excel_data_1)):
worksheet1.col(i).width = 2560 * 3
# 行,列, 内容, 样式
worksheet1.write(0, i, excel_data_1[i])
workbook.save(os_path)
# 判断工作表是否存在
# 存在,开始往表格中添加数据(写入数据)
if os.path.exists(os_path):
# 打开工作薄
workbook = xlrd.open_workbook(os_path)
# 获取工作薄中所有表的个数
sheets = workbook.sheet_names()
for i in range(len(sheets)):
for name in data_dict.keys():
worksheet = workbook.sheet_by_name(sheets[i])
# 获取工作薄中所有表中的表名与数据名对比
if worksheet.name == name:
# 获取表中已存在的行数
rows_old = worksheet.nrows
# 将xlrd对象拷贝转化为xlwt对象
new_workbook = copy(workbook)
# 获取转化后的工作薄中的第i张表
new_worksheet = new_workbook.get_sheet(i)
for num in range(0, len(data_dict[name])):
new_worksheet.write(rows_old, num, data_dict[name][num])
new_workbook.save(os_path)
def run(self):
"""
启动运行
:return:
"""
self.parse_start_url()
if __name__ == '__main__':
# 创建该类的对象
t = TXSpider()
# 通过实例方法,进行调用
t.run()

原创不易,欢迎一键三连
祝大家学习python顺利!!
原文链接:https://blog.csdn.net/weixin_54733110/article/details/118553377
所属网站分类: 技术文章 > 博客
作者:火腿快跑
链接:http://www.pythonpdf.com/blog/article/75/a3568c2f099933a21360/
来源:编程知识网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)